
Deephub

已加入开发者社区940天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

一代宗师
一代宗师



我关注的人
粉丝


技术能力
兴趣领域
擅长领域
技术认证
暂时未有相关云产品技术能力~
公众号 Deephub-IMBA
暂无精选文章
暂无更多信息
2025年07月
-
07.05 11:51:08
 发表了文章
2025-07-05 11:51:08
发表了文章
2025-07-05 11:51:08
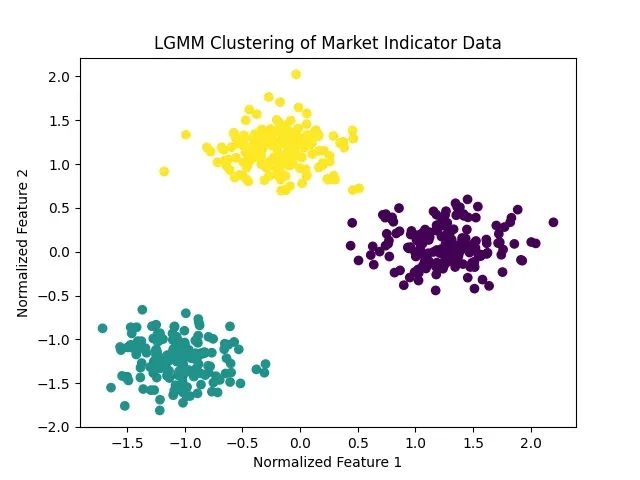
量化交易隐藏模式识别方法:用潜在高斯混合模型识别交易机会
本文将从技术实现角度阐述LGMM相对于传统方法的优势,通过图表对比分析展示其效果,并详细说明量化分析师和技术分析师如何应用此方法优化投资决策。 -
07.04 15:55:10发表了文章
2025-07-04 15:55:10
掌握这10个Jupyter魔法命令,让你的数据分析效率提升3倍
本文将详细介绍十个在实际数据科学项目中最为实用的魔法命令,并通过传粉者数据分析项目进行具体演示。 -
07.03 13:10:45发表了文章
2025-07-03 13:10:45
大语言模型也可以进行图像分割:使用Gemini实现工业异物检测完整代码示例
本文将通过一个实际应用场景——工业传送带异物检测,详细介绍如何利用Gemini的图像分割能力构建完整的解决方案。 -
07.02 10:43:20发表了文章
2025-07-02 10:43:20
CUDA性能优化实战:7个步骤让并行归约算法提升10倍效率
https://avoid.overfit.cn/post/af59d0a6ce474b8fa7a8eafb2117a404 -
07.01 10:56:00发表了文章
2025-07-01 10:56:00
Python时间序列平滑技术完全指南:6种主流方法原理与实战应用
时间序列数据分析中,噪声干扰普遍存在,影响趋势提取。本文系统解析六种常用平滑技术——移动平均、EMA、Savitzky-Golay滤波器、LOESS回归、高斯滤波与卡尔曼滤波,从原理、参数配置、适用场景及优缺点多角度对比,并引入RPR指标量化平滑效果,助力方法选择与优化。


2025年06月
-
06.30 10:20:40发表了文章
2025-06-30 10:20:40
Python AutoML框架选型攻略:7个工具性能对比与应用指南
本文系统介绍了主流Python AutoML库的技术特点与适用场景,涵盖AutoGluon、PyCaret、TPOT、Auto-sklearn、H2O AutoML及AutoKeras等工具,帮助开发者根据项目需求高效选择自动化机器学习方案。 -
06.29 11:34:36发表了文章
2025-06-29 11:34:36
大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
本文通过实际案例演示特征工程在回归任务中的应用效果,重点分析包含数值型、分类型和时间序列特征的大规模表格数据集的处理方法。 -
06.28 11:26:58发表了文章
2025-06-28 11:26:58
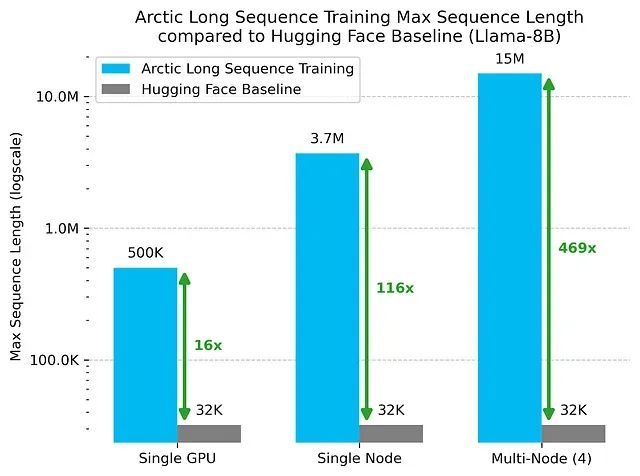
Arctic长序列训练技术:百万级Token序列的可扩展高效训练方法
Arctic长序列训练(Arctic Long Sequence Training, ALST)技术能够在4个H100节点上对Meta的Llama-8B模型进行高达1500万token序列的训练,使得长序列训练在标准GPU集群甚至单个GPU上都能实现快速、高效且易于部署的执行。 -
06.27 10:41:56发表了文章
2025-06-27 10:41:56
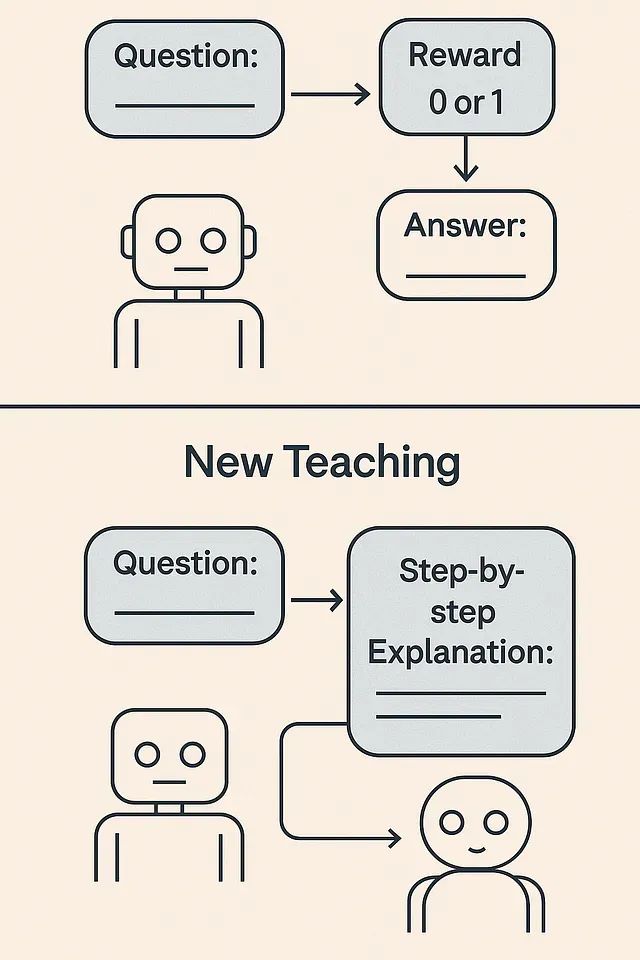
小模型当老师效果更好:借助RLTs方法7B参数击败671B,训练成本暴降99%
强化学习教师模型代表了训练推理语言模型的范式转变。通过从答案开始并专注于解释生成,RLT将训练过程转化为师生协作游戏,实现多方共赢:教师学会有效教学,学生从定制化课程中受益,工程师获得性能更好且成本更低的模型解决方案。 -
06.26 10:16:12发表了文章
2025-06-26 10:16:12
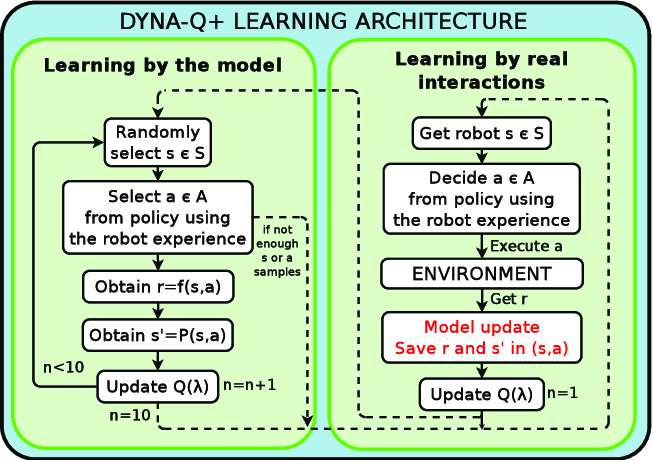
基于Dyna-Q强化学习的智能营销系统:融合贝叶斯生存模型与Transformer注意力机制的电商客户重参与策略优化
本文提出了一个集成三种核心技术的下一代智能优惠券分发系统:基于贝叶斯生存模型的重购概率预测、采用注意力机制的Transformer利润预测模型,以及用于策略持续优化的Dyna-Q强化学习代理。 -
06.25 10:49:33发表了文章
2025-06-25 10:49:33
解决语义搜索痛点,基于对比学习的领域特定文本嵌入模型微调实践
本文深入探讨了基于对比学习的嵌入模型微调技术,并通过AI职位匹配的实际案例验证了该方法的有效性。微调后的模型在测试集上实现了100%的准确率,充分证明了针对特定领域进行模型优化的必要性和可行性。 -
06.24 11:01:57发表了文章
2025-06-24 11:01:57
基于LSTM自编码器与KMeans聚类的时间序列无监督异常检测方法
本文提出的基于LSTM自编码器和KMeans聚类的组合方法,通过整合深度学习的序列建模能力与无监督聚类的模式分组优势,实现了对时间序列数据中异常模式的有效检测,且无需依赖标注的异常样本进行监督学习。 -
06.23 10:30:58发表了文章
2025-06-23 10:30:58
混合效应模型原理与实现:从理论到代码的完整解析
混合效应模型并非神秘的技术,而是普通回归方法在层次化结构建模方面的原理性扩展。这种理解将成为机器学习工具箱中下一个技术突破的重要基础。 -
06.22 10:46:01发表了文章
2025-06-22 10:46:01
Chonkie:面向大语言模型的轻量级文本分块处理库
Chonkie是一个专为大语言模型(LLM)应用场景设计的轻量级文本分块处理库,提供高效的文本分割和管理解决方案。该库采用最小依赖设计理念,特别适用于现实世界的自然语言处理管道。本文将详细介绍Chonkie的核心功能、设计理念以及五种主要的文本分块策略。 -
06.21 09:54:30发表了文章
2025-06-21 09:54:30
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统
本研究通过实验演示了异常标记如何逐步完善异常检测方案和主要分类模型在欺诈检测中的应用。实验结果表明,Isolation Forest作为一个强大的异常检测模型,无需显式建模正常模式即可有效工作,在处理未见风险事件方面具有显著优势。 -
06.20 14:14:57发表了文章
2025-06-20 14:14:57
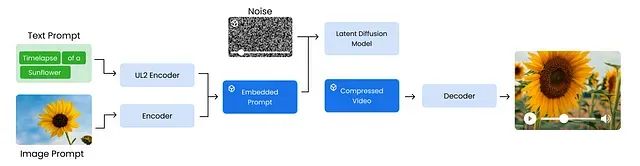
从零复现Google Veo 3:从数据预处理到视频生成的完整Python代码实现指南
本文详细介绍了一个简化版 Veo 3 文本到视频生成模型的构建过程。首先进行了数据预处理,涵盖了去重、不安全内容过滤、质量合规性检查以及数据标注等环节。 -
06.18 10:42:59发表了文章
2025-06-18 10:42:59
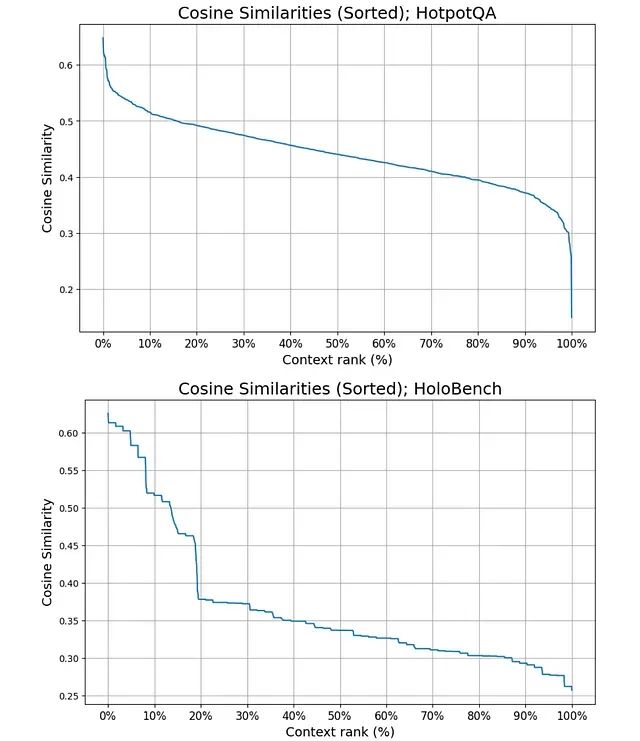
Adaptive-k 检索:RAG 系统中自适应上下文长度选择的新方法
本文介绍 Adaptive-k 检索技术,这是一种通过相似性分布分析动态确定最优上下文规模的即插即用方法,该技术在显著降低 token 消耗的同时实现了检索增强生成系统的性能提升。 -
06.17 10:35:13发表了文章
2025-06-17 10:35:13
基于时间图神经网络多的产品需求预测:跨序列依赖性建模实战指南
本文展示了如何通过学习稀疏影响图、应用图卷积融合邻居节点信息,并结合时间卷积捕获演化模式的完整技术路径,深入分析每个步骤的机制原理和数学基础。 -
06.16 09:58:41发表了文章
2025-06-16 09:58:41
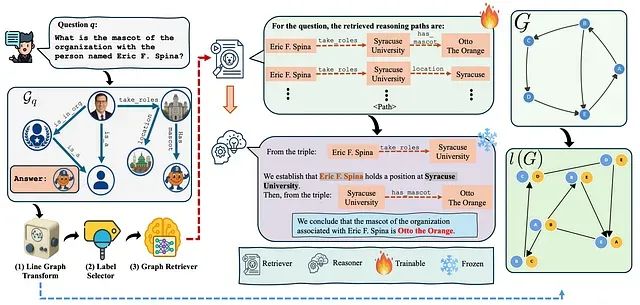
解决RAG检索瓶颈:RAPL线图转换让知识图谱检索准确率提升40%
本文探讨了RAPL框架,一种创新的人工智能架构,用于改进知识图谱环境下的检索增强生成系统。RAPL通过线图转换和合理化监督技术,构建高效且可泛化的检索器,显著提升大型语言模型在知识问答中的准确性和可解释性。文章分析了现有RAG系统的缺陷,即最短路径并非总是合理路径,并提出RAPL的三步解决方案:利用大型语言模型生成高质量训练数据、将知识图谱转换为线图以实现基于路径的推理,以及通过双向图神经网络进行路径检索。实验结果表明,RAPL不仅提高了检索精度,还缩小了小型与大型语言模型间的性能差距,推动了更高效、透明的AI系统发展。 -
06.15 10:24:41发表了文章
2025-06-15 10:24:41
ProRL:基于长期强化学习让1.5B小模型推理能力超越7B大模型
该研究通过长期强化学习训练(ProRL)挑战了强化学习仅能放大模型输出的传统观点,证明其能使基础模型发现全新推理策略。ProRL体系包含KL散度控制、参考策略重置及多元化任务训练集。核心算法GRPO优化了传统PPO,缓解熵坍塌问题并提升探索能力。Nemotron-Research-Reasoning-Qwen-1.5B模型基于此方法训练,在数学、编程、STEM等领域显著超越基础模型,性能提升达15.7%-25.9%,并在分布外任务中展现更强泛化能力。 -
06.14 08:52:59发表了文章
2025-06-14 08:52:59
PyTorch + MLFlow 实战:从零构建可追踪的深度学习模型训练系统
本文通过使用 Kaggle 数据集训练情感分析模型的实例,详细演示了如何将 PyTorch 与 MLFlow 进行深度集成,实现完整的实验跟踪、模型记录和结果可复现性管理。文章将系统性地介绍训练代码的核心组件,展示指标和工件的记录方法,并提供 MLFlow UI 的详细界面截图。 -
06.13 14:01:08发表了文章
2025-06-13 14:01:08
Python 3D数据可视化:7个实用案例助你快速上手
本文介绍了基于 Python Matplotlib 库的七种三维数据可视化技术,涵盖线性绘图、散点图、曲面图、线框图、等高线图、三角剖分及莫比乌斯带建模。通过具体代码示例和输出结果,展示了如何配置三维投影环境并实现复杂数据的空间表示。这些方法广泛应用于科学计算、数据分析与工程领域,帮助揭示多维数据中的空间关系与规律,为深入分析提供技术支持。 -
06.12 14:32:19发表了文章
2025-06-12 14:32:19
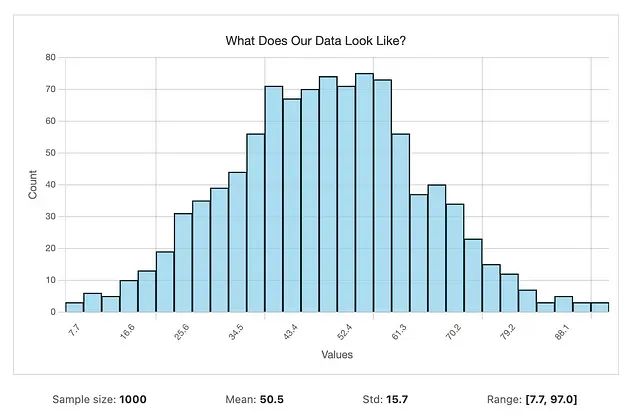
数据分布不明确?5个方法识别数据分布,快速找到数据的真实规律
本文深入探讨了数据科学中分布识别的重要性及其实践方法。作为数据分析的基础环节,分布识别影响后续模型性能与分析可靠性。文章从直方图的可视化入手,介绍如何通过Python代码实现分布特征的初步观察,并系统化地讲解参数估计、统计检验及distfit库的应用。同时,针对离散数据、非参数方法和Bootstrap验证等专题展开讨论,强调业务逻辑与统计结果结合的重要性。最后指出,正确识别分布有助于异常检测、数据生成及预测分析等领域,为决策提供可靠依据。作者倡导在实践中平衡模型复杂度与实用性,重视对数据本质的理解。 -
06.11 10:03:29发表了文章
2025-06-11 10:03:29
SnapViewer:解决PyTorch官方内存工具卡死问题,实现高效可视化
深度学习训练中,GPU内存不足(OOM)是常见难题。PyTorch虽提供内存分析工具,但其官方可视化方案存在严重性能瓶颈,尤其在处理大型模型快照时表现极差。为解决这一问题,SnapViewer项目应运而生。该项目通过将内存快照解析为三角形网格结构并借助成熟渲染库,充分发挥GPU并行计算优势,大幅提升大型快照处理效率。此外,SnapViewer优化了数据处理流水线,采用Rust和Python结合的方式,实现高效压缩与解析。项目不仅解决了现有工具的性能缺陷,还为开发者提供了更流畅的内存分析体验,对类似性能优化项目具有重要参考价值。 -
06.10 10:26:39发表了文章
2025-06-10 10:26:39
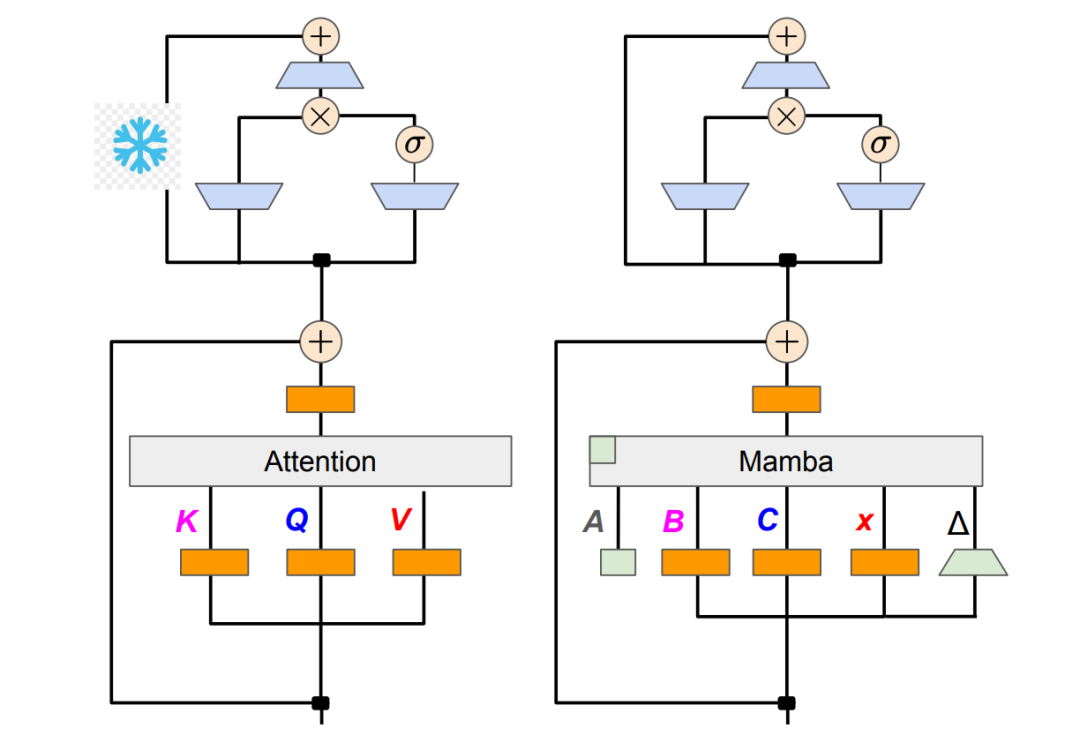
提升长序列建模效率:Mamba+交叉注意力架构完整指南
本文探讨了Mamba架构中交叉注意力机制的集成方法,Mamba是一种基于选择性状态空间模型的新型序列建模架构,擅长处理长序列。通过引入交叉注意力,Mamba增强了多模态信息融合和条件生成能力。文章从理论基础、技术实现、性能分析及应用场景等方面,详细阐述了该混合架构的特点与前景,同时分析了其在计算效率、训练稳定性等方面的挑战,并展望了未来优化方向,如动态路由机制和多模态扩展,为高效序列建模提供了新思路。 -
06.09 12:30:45发表了文章
2025-06-09 12:30:45
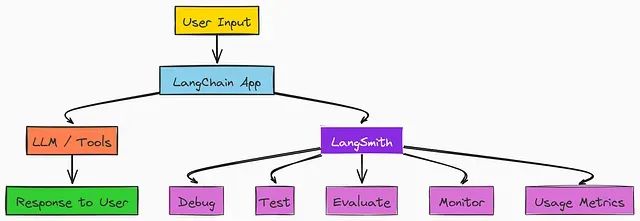
LangGraph实战教程:构建会思考、能记忆、可人工干预的多智能体AI系统
本文介绍了使用LangGraph和LangSmith构建企业级多智能体AI系统的完整流程。从简单的ReAct智能体开始,逐步扩展至包含身份验证、人工干预、长期内存管理和性能评估的复杂架构。文章详细讲解了状态管理、工具集成、条件流程控制等关键技术,并对比了监督者架构与群体架构的优劣。通过系统化的方法,展示了如何构建可靠、可扩展的AI系统,为现代AI应用开发提供了坚实基础。*作者:Fareed Khan* -
06.08 10:23:10发表了文章
2025-06-08 10:23:10
DROPP算法详解:专为时间序列和空间数据优化的PCA降维方案
DROPP(Dimensionality Reduction for Ordered Points via PCA)是一种专为有序数据设计的降维方法,通过结合协方差分析与高斯核函数调整,有效融入数据顺序特性。本文详细解析了DROPP的理论基础、实现步骤及其应用。算法核心在于利用相邻元素间的相似性特征,关注局部邻域信息以降低噪声影响,适用于时间序列或空间序列数据。文中通过模拟数据示例展示了算法的具体实现过程,并总结了其在气候研究和分子动力学等领域的广泛应用潜力。 -
06.07 10:19:55发表了文章
2025-06-07 10:19:55
朴素贝叶斯处理混合数据类型,基于投票与堆叠集成的系统化方法理论基础与实践应用
本文探讨了朴素贝叶斯算法在处理混合数据类型中的应用,通过投票和堆叠集成方法构建分类框架。实验基于电信客户流失数据集,验证了该方法的有效性。文章详细分析了算法的数学理论基础、条件独立性假设及参数估计方法,并针对二元、类别、多项式和高斯分布特征设计专门化流水线。实验结果表明,集成学习显著提升了分类性能,但也存在特征分类自动化程度低和计算开销大的局限性。作者还探讨了特征工程、深度学习等替代方案,为未来研究提供了方向。(239字) -
06.06 10:03:23发表了文章
2025-06-06 10:03:23
提升模型泛化能力:PyTorch的L1、L2、ElasticNet正则化技术深度解析与代码实现
本文将深入探讨L1、L2和ElasticNet正则化技术,重点关注其在PyTorch框架中的具体实现。关于这些技术的理论基础,建议读者参考相关理论文献以获得更深入的理解。 -
06.05 10:21:38发表了文章
2025-06-05 10:21:38
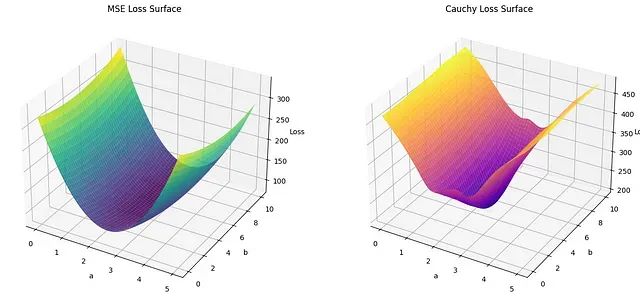
让回归模型不再被异常值"带跑偏",MSE和Cauchy损失函数在噪声数据环境下的实战对比
本文探讨了MSE与Cauchy损失函数在线性回归中的表现,特别是在含噪声数据环境下的差异。研究发现,MSE虽具良好数学性质,但对异常值敏感;而Cauchy通过其对数惩罚机制降低异常值影响,展现出更强稳定性。实验结果表明,Cauchy损失函数在处理含噪声数据时参数估计更接近真实值,为实际应用提供了更鲁棒的选择。 -
06.04 13:42:04发表了文章
2025-06-04 13:42:04
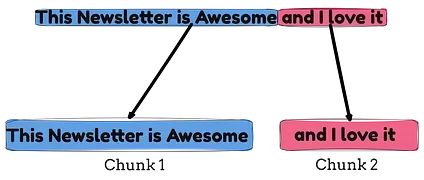
RAG系统文本分块优化指南:9种实用策略让检索精度翻倍
本文深入探讨了RAG系统中的九种文本分块策略。固定大小分块简单高效,但可能破坏语义完整性;基于句子和语义的分块保留上下文,适合语义任务;递归与滑动窗口分块灵活控制大小;层次化和主题分块适用于结构化内容;特定模态分块处理多媒体文档;智能代理分块则通过大语言模型实现动态优化。开发者需根据文档类型、需求及资源选择合适策略,以提升RAG系统的性能和用户体验。作者Cornellius Yudha Wijaya详细分析了各策略的技术特点与应用场景。 -
06.03 13:51:21发表了文章
2025-06-03 13:51:21
文本聚类效果差?5种主流算法性能测试帮你找到最佳方案
本文探讨了自然语言处理中句子嵌入的聚类技术,使用Billingsmoore数据集(925个英语句子)进行实验。通过生成句子嵌入向量并可视化分析,对比了K-Means、DBSCAN、HDBSCAN、凝聚型层次聚类和谱聚类等算法的表现。结果表明,K-Means适合已知聚类数量的场景,DBSCAN和HDBSCAN适用于未知聚类数量且存在异常值的情况,而谱聚类在句子嵌入领域表现不佳。最终建议根据数据特征和计算资源选择合适的算法以实现高质量聚类。 -
06.02 16:13:31发表了文章
2025-06-02 16:13:31
BayesFlow:基于神经网络的摊销贝叶斯推断框架
BayesFlow 是一个基于 Python 的开源框架,利用摊销神经网络加速贝叶斯推断,解决传统方法计算复杂度高的问题。它通过训练神经网络学习从数据到参数的映射,实现毫秒级实时推断。核心组件包括摘要网络、后验网络和似然网络,支持摊销后验估计、模型比较及错误检测等功能。适用于流行病学、神经科学、地震学等领域,为仿真驱动的科研与工程提供高效解决方案。其模块化设计兼顾易用性与灵活性,推动贝叶斯推断从理论走向实践。 -
06.01 19:14:41发表了文章
2025-06-01 19:14:41
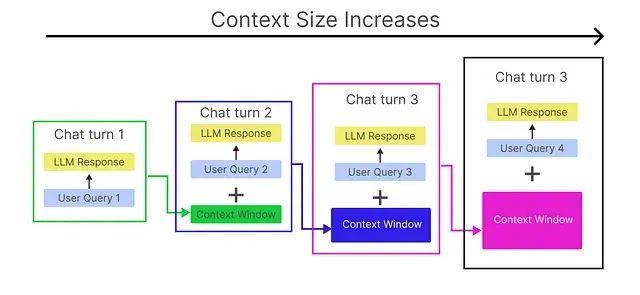
基于内存高效算法的 LLM Token 优化:一个有效降低 API 成本的技术方案
本文探讨了在构建对话系统时如何通过一种内存高效算法降低大语言模型(LLM)的Token消耗和运营成本。传统方法中,随着对话深度增加,Token消耗呈指数级增长,导致成本上升。






2025年05月
-
05.31 17:34:53发表了文章
2025-05-31 17:34:53
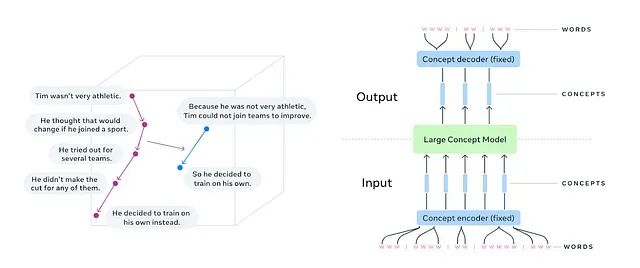
基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
本文探讨了在企业数字化转型中,大型概念模型(LCMs)与图神经网络结合处理非结构化文本数据的技术方案。LCMs突破传统词汇级处理局限,以概念级语义理解为核心,增强情感分析、实体识别和主题建模能力。通过构建基于LangGraph的混合符号-语义处理管道,整合符号方法的结构化优势与语义方法的理解深度,实现精准的文本分析。具体应用中,该架构通过预处理、图构建、嵌入生成及GNN推理等模块,完成客户反馈的情感分类与主题聚类。最终,LangGraph工作流编排确保各模块高效协作,为企业提供可解释性强、业务价值高的分析结果。此技术融合为挖掘非结构化数据价值、支持数据驱动决策提供了创新路径。 -
05.30 09:56:14发表了文章
2025-05-30 09:56:14
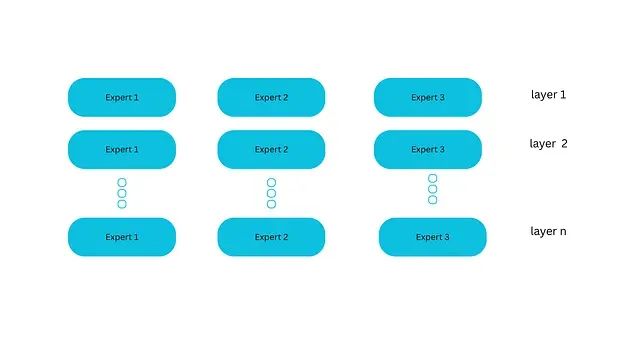
为什么混合专家模型(MoE)如此高效:从架构原理到技术实现全解析
本文深入探讨了混合专家(MoE)架构在大型语言模型中的应用与技术原理。MoE通过稀疏激活机制,在保持模型高效性的同时实现参数规模的大幅扩展,已成为LLM发展的关键趋势。文章分析了MoE的核心组件,包括专家网络与路由机制,并对比了密集与稀疏MoE的特点。同时,详细介绍了Mixtral、Grok、DBRX和DeepSeek等代表性模型的技术特点及创新。MoE不仅解决了传统模型扩展成本高昂的问题,还展现出专业化与适应性强的优势,未来有望推动AI工具更广泛的应用。 -
05.29 15:49:21发表了文章
2025-05-29 15:49:21
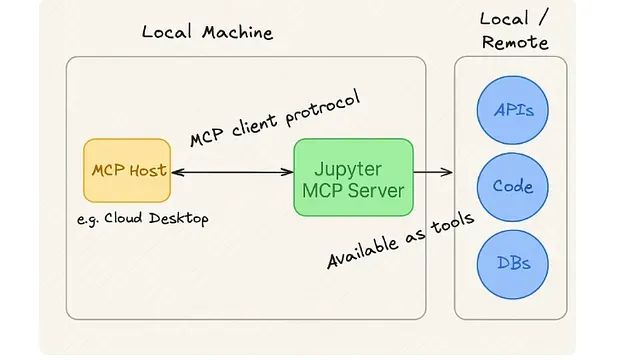
Jupyter MCP服务器部署实战:AI模型与Python环境无缝集成教程
Jupyter MCP服务器基于模型上下文协议(MCP),实现大型语言模型与Jupyter环境的无缝集成。它通过标准化接口,让AI模型安全访问和操作Jupyter核心组件,如内核、文件系统和终端。本文深入解析其技术架构、功能特性及部署方法。MCP服务器解决了传统AI模型缺乏实时上下文感知的问题,支持代码执行、变量状态获取、文件管理等功能,提升编程效率。同时,严格的权限控制确保了安全性。作为智能化交互工具,Jupyter MCP为动态计算环境与AI模型之间搭建了高效桥梁。 -
05.28 14:10:15发表了文章
2025-05-28 14:10:15
图神经网络在信息检索重排序中的应用:原理、架构与Python代码解析
本文探讨了基于图的重排序方法在信息检索领域的应用与前景。传统两阶段检索架构中,初始检索速度快但结果可能含噪声,重排序阶段通过强大语言模型提升精度,但仍面临复杂需求挑战 -
05.27 10:02:12发表了文章
2025-05-27 10:02:12
CUDA重大更新:原生Python可直接编写高性能GPU程序
NVIDIA在2025年GTC大会上宣布CUDA并行计算平台正式支持原生Python编程,消除了Python开发者进入GPU加速领域的技术壁垒。这一突破通过重新设计CUDA开发模型,引入CUDA Core、cuPyNumeric、NVMath Python等核心组件,实现了Python与GPU加速的深度集成。开发者可直接用Python语法进行高性能并行计算,显著降低门槛,扩展CUDA生态,推动人工智能、科学计算等领域创新。此更新标志着CUDA向更包容的语言生态系统转型,未来还将支持Rust、Julia等语言。 -
05.26 13:28:24发表了文章
2025-05-26 13:28:24
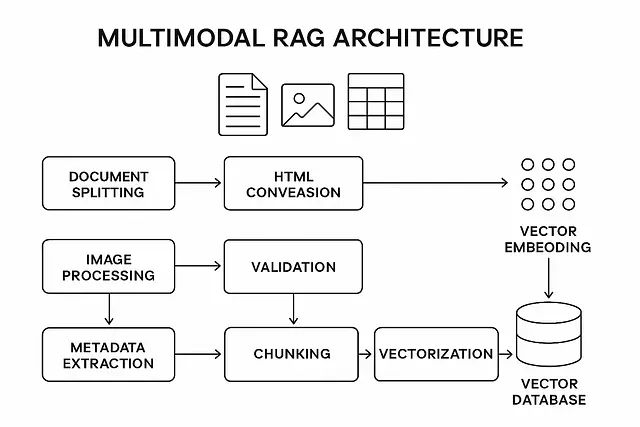
多模态RAG实战指南:完整Python代码实现AI同时理解图片、表格和文本
本文探讨了多模态RAG系统的最优实现方案,通过模态特定处理与后期融合技术,在性能、准确性和复杂度间达成平衡。系统包含文档分割、内容提取、HTML转换、语义分块及向量化存储五大模块,有效保留结构和关系信息。相比传统方法,该方案显著提升了复杂查询的检索精度(+23%),并支持灵活升级。文章还介绍了查询处理机制与优势对比,为构建高效多模态RAG系统提供了实践指导。 -
05.25 11:11:16发表了文章
2025-05-25 11:11:16
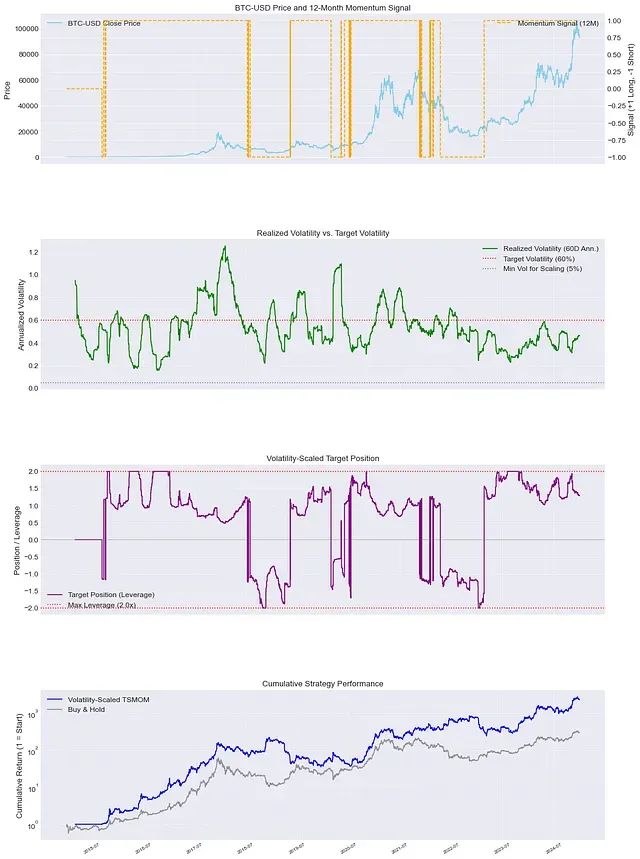
Python实现时间序列动量策略:波动率标准化让量化交易收益更平稳
时间序列动量策略(TSMOM)是一种基于资产价格趋势的量化交易方法,通过建立多头或空头头寸捕捉市场惯性。然而,传统TSMOM策略因风险敞口不稳定而面临收益波动问题。波动率调整技术通过动态调节头寸规模,维持恒定风险水平,优化了策略表现。本文系统分析了波动率调整TSMOM的原理、实施步骤及优势,强调其在现代量化投资中的重要地位,并探讨关键参数设定与实际应用考量,为投资者提供更平稳的风险管理体验。 -
05.24 10:44:39发表了文章
2025-05-24 10:44:39
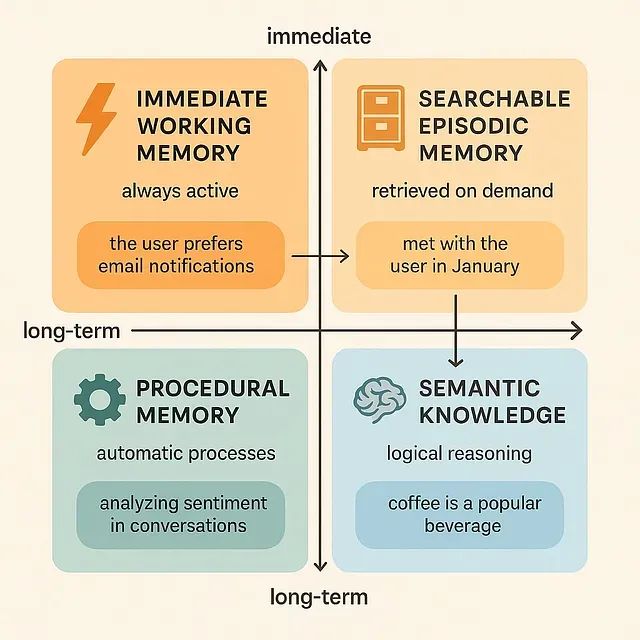
构建智能AI记忆系统:多智能体系统记忆机制的设计与技术实现
本文探讨了多智能体系统中记忆机制的设计与实现,提出构建精细化记忆体系以模拟人类认知过程。文章分析了上下文窗口限制的技术挑战,并介绍了四种记忆类型:即时工作记忆、情节记忆、程序性记忆和语义知识系统。通过基于文件的工作上下文记忆、模型上下文协议的数据库集成以及RAG系统等技术方案,满足不同记忆需求。此外,高级技术如动态示例选择、记忆蒸馏和冲突解决机制进一步提升系统智能化水平。总结指出,这些技术推动智能体向更接近人类认知的复杂记忆处理机制发展,为人工智能开辟新路径。 -
05.23 22:16:54发表了文章
2025-05-23 22:16:54
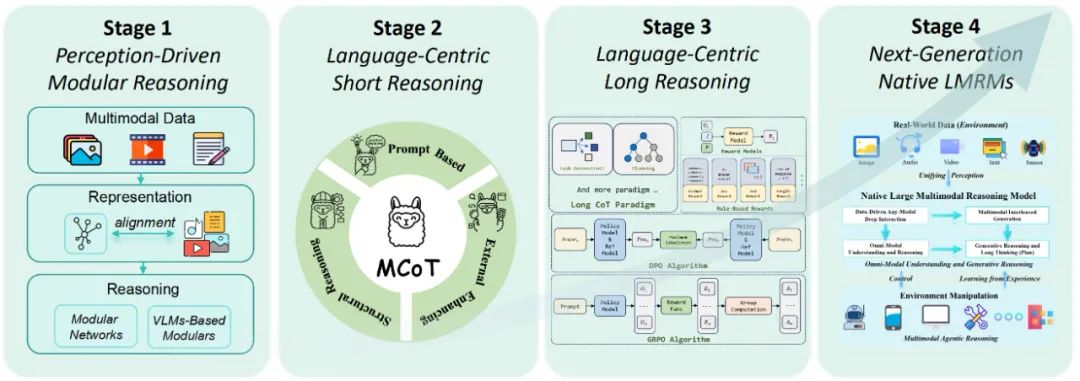
大型多模态推理模型技术演进综述:从模块化架构到原生推理能力的综合分析
该研究系统梳理了大型多模态推理模型(LMRMs)的技术发展,从早期模块化架构到统一的语言中心框架,提出原生LMRMs(N-LMRMs)的前沿概念。论文划分三个技术演进阶段及一个前瞻性范式,深入探讨关键挑战与评估基准,为构建复杂动态环境中的稳健AI系统提供理论框架。未来方向聚焦全模态泛化、深度推理与智能体行为,推动跨模态融合与自主交互能力的发展。 -
05.22 10:15:35发表了文章
2025-05-22 10:15:35
解读 Python 3.14:模板字符串、惰性类型、Zstd压缩等7大核心功能升级
Python 3.14 引入了七大核心技术特性,大幅提升开发效率与应用安全性。其中包括:t-strings(PEP 750)提供更安全灵活的字符串处理;类型注解惰性求值(PEP 649)优化启动性能;外部调试器API标准化(PEP 768)增强调试体验;原生支持Zstandard压缩算法(PEP 784)提高效率;REPL交互环境升级更友好;UUID模块扩展支持新标准并优化性能;finally块语义强化(PEP 765)确保资源清理可靠性。这些改进使Python在后端开发、数据科学等领域更具竞争力。 -
05.21 10:28:18发表了文章
2025-05-21 10:28:18
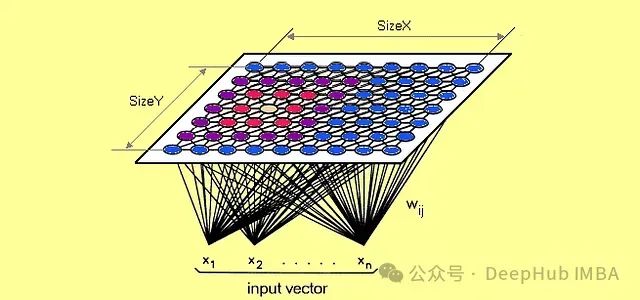
面向概念漂移的动态自组织映射(SOM)及其在金融风险预警中的效能评估
本文探讨了自组织映射(SOM)在金融数据分析与异常检测中的应用。SOM作为一种无监督神经网络模型,可将高维数据投影到低维网格中,具备持续学习和可视化解释能力,能有效应对实时数据更新和概念漂移问题。文章分析了SOM在银行欺诈检测、流动性危机预警等场景中的优势,并通过量化误差(QE)、拓扑误差(TE)及BMU激活频率等机制实现异常检测。动态SOM相比传统静态方法,更能适应金融市场变化,提供早期预警支持。附带的Python实现展示了SOM在模拟银行业务数据中的应用效果。 -
05.20 10:31:29发表了文章
2025-05-20 10:31:29
高效处理多维数组:einsum()函数从入门到精通
本文深入解析了NumPy中的`einsum()`函数,从基础语法到高级应用全面展开。文章首先介绍了爱因斯坦求和约定的数学基础,解释了`einsum()`如何通过简洁的索引符号实现复杂的多维数组运算。 -
05.18 10:44:52发表了文章
2025-05-18 10:44:52
基于马尔可夫链的状态转换,用概率模型预测股市走势
本文探讨了马尔可夫链在股市分析中的应用,通过定义市场状态和构建转移矩阵,揭示短期波动与长期趋势的概率特征。模型基于“无记忆性”假设,量化状态转换概率,帮助评估风险、识别模式并制定策略。例如,计算稳态分布可预测市场长期平衡态。尽管模型简化了复杂动态,但仍为投资决策提供了数据支持。同时,文章强调其局限性,如外部冲击影响和状态定义主观性,建议结合其他工具综合分析。未来可探索与机器学习融合,提升市场理解深度。 -
05.17 10:05:10发表了文章
2025-05-17 10:05:10
深入解析torch.compile:提升PyTorch模型性能、高效解决常见问题
PyTorch 2.0推出的`torch.compile`功能为深度学习模型带来了显著的性能优化能力。本文从实用角度出发,详细介绍了`torch.compile`的核心技巧与应用场景,涵盖模型复杂度评估、可编译组件分析、系统化调试策略及性能优化高级技巧等内容。通过解决图断裂、重编译频繁等问题,并结合分布式训练和NCCL通信优化,开发者可以有效提升日常开发效率与模型性能。文章为PyTorch用户提供了全面的指导,助力充分挖掘`torch.compile`的潜力。



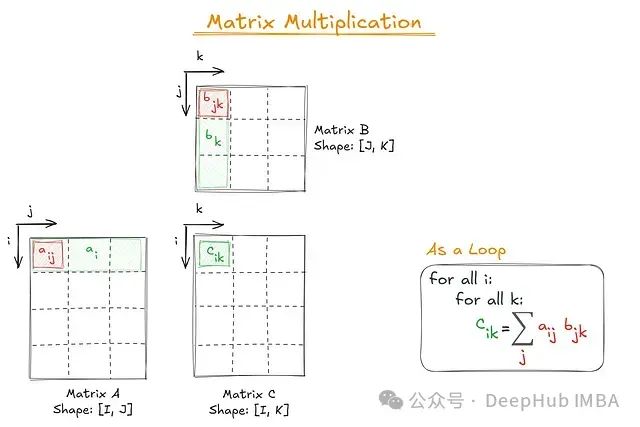
-
发表了文章
2025-07-05
量化交易隐藏模式识别方法:用潜在高斯混合模型识别交易机会
-
发表了文章
2025-07-04
掌握这10个Jupyter魔法命令,让你的数据分析效率提升3倍
-
发表了文章
2025-07-03
大语言模型也可以进行图像分割:使用Gemini实现工业异物检测完整代码示例
-
发表了文章
2025-07-02
CUDA性能优化实战:7个步骤让并行归约算法提升10倍效率
-
发表了文章
2025-07-01
Python时间序列平滑技术完全指南:6种主流方法原理与实战应用
-
发表了文章
2025-06-30
Python AutoML框架选型攻略:7个工具性能对比与应用指南
-
发表了文章
2025-06-29
大数据集特征工程实践:将54万样本预测误差降低68%的技术路径与代码实现详解
-
发表了文章
2025-06-28
Arctic长序列训练技术:百万级Token序列的可扩展高效训练方法
-
发表了文章
2025-06-27
小模型当老师效果更好:借助RLTs方法7B参数击败671B,训练成本暴降99%
-
发表了文章
2025-06-26
基于Dyna-Q强化学习的智能营销系统:融合贝叶斯生存模型与Transformer注意力机制的电商客户重参与策略优化
-
发表了文章
2025-06-25
解决语义搜索痛点,基于对比学习的领域特定文本嵌入模型微调实践
-
发表了文章
2025-06-24
基于LSTM自编码器与KMeans聚类的时间序列无监督异常检测方法
-
发表了文章
2025-06-23
混合效应模型原理与实现:从理论到代码的完整解析
-
发表了文章
2025-06-22
Chonkie:面向大语言模型的轻量级文本分块处理库
-
发表了文章
2025-06-21
机器学习异常检测实战:用Isolation Forest快速构建无标签异常检测系统
-
发表了文章
2025-06-20
从零复现Google Veo 3:从数据预处理到视频生成的完整Python代码实现指南
-
发表了文章
2025-06-18
Adaptive-k 检索:RAG 系统中自适应上下文长度选择的新方法
-
发表了文章
2025-06-17
基于时间图神经网络多的产品需求预测:跨序列依赖性建模实战指南
-
发表了文章
2025-06-16
解决RAG检索瓶颈:RAPL线图转换让知识图谱检索准确率提升40%
-
发表了文章
2025-06-15
ProRL:基于长期强化学习让1.5B小模型推理能力超越7B大模型
滑动查看更多
暂无更多信息
暂无更多信息