
如何可以让 Kubernetes 运维提效90% ?
 6720积分,定制充电器*10
6720积分,定制充电器*10
Kubernetes 的复杂性依旧是容器化业务部署的一大挑战,而更高效地运维 Kubernetes 已逐渐成为普遍诉求 。ACK 智能托管模式是 ACK 基于 ACK托管集群 Pro版全新升级的 Kubernetes 集群管理模式,开启后,运维人员仅需进行简单的网络规划配置,即可快速创建一个符合最佳实践的 Kubernetes 集群,具备全面托管运维、智能资源供给和基础软件栈优化等特点。
通过实践体验 ACK Pro 智能托管模式部署工作负载后,你会对其有何见解?点击链接立即体验:使用ACK Auto Mode集群快速部署Nginx工作负载
本期话题:通过体验 使用ACK Auto Mode集群快速部署Nginx工作负载 的动手实践后,你认为 ACK 智能托管模式对运维工作能带来哪些便利?在评论区留下你的想法与建议吧~
本期奖品:截止2025年6月30日18时,参与本期话题讨论,将会选出 10 个优质回答获得阿里云-制糖工厂涂鸦充电器,奖品前往积分商城进行兑换。快来参加讨论吧~
优质讨论获奖规则:1.完整分享动手实践体验过程与体验感想,并提出改进建议或想追加的功能2.回答非 AI 生成。
未获得实物礼品的参与者将有机会获得 10-100 积分的奖励,所获积分可前往积分商城进行礼品兑换。

注:楼层需为有效回答(符合互动主题),灌水/同人账号/复制抄袭/不当言论等回答将不予发奖。阿里云开发者社区有权对回答进行删除。获奖名单将于活动结束后5个工作日内公布,奖品将于7个工作日内进行发放,节假日顺延。奖品发放后请中奖用户及时关注站内信并领取兑换,若超时未领取则默认放弃领奖,逾期将不进行补发。
获奖公告
本次活动截止到2025年6月30日,共收获84条回复,感谢各位开发者的倾情参与和贡献!
根据奖项规则设置,我们从交流深度/回答质量/实验成果质量/回复原创性等维度综合考量,评选出本次获奖用户,详情如下:
优质评论奖(3名,阿里云-制糖工厂涂鸦充电器):GeminiMp、丧心病狂的雷克斯大人、一键难忘
未获得实物礼品的参与者均可获得 10-200 积分的奖励,所获积分可前往积分商城进行礼品兑换。
恭喜以上获奖用户,后续将有运营同学联系收集物流信息,请注意查收站内消息,奖品将于名单公布后的7个工作日内发
放,如遇节假日则顺延。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
- 极致简化集群管理
ACK 智能托管模式极大程度地自动化了 Kubernetes 集群的底层基础设施管理。这包括:
节点生命周期管理:您不再需要手动添加、删除、扩缩容节点,系统会根据工作负载的需求自动调整节点数量。例如,部署 Nginx 工作负载时,如果流量增加,ACK Auto Mode 会自动增加计算资源以应对。
版本升级和补丁:Kubernetes 主版本和节点操作系统(OS)的升级、安全补丁的安装都由阿里云自动完成,减少了手动操作的复杂性和潜在风险。
基础设施运维:底层计算、网络、存储等基础设施的日常维护、故障排查和修复都由平台负责,运维人员可以完全摆脱这些繁琐的工作。
- 降低运维成本和复杂度
通过自动化和托管,ACK Auto Mode 有效地降低了企业的运维成本和对专业 Kubernetes 运维人员的依赖:
人力成本节约:无需配备专门的团队来维护底层K8s集群和节点,减少了人力投入。
学习曲线降低:对于不熟悉 Kubernetes 复杂性的团队来说,可以直接部署应用,而无需深入了解集群的内部机制,降低了使用门槛。
避免错误:自动化操作减少了人工干预,从而降低了因误操作而导致系统不稳定的风险。
- 提升业务连续性和弹性
ACK Auto Mode 内置的智能调度和弹性伸缩能力确保了业务的高可用和弹性:
自动弹性伸缩:无论是 Nginx 这类负载均衡应用还是其他业务,当流量高峰到来时,集群能够自动扩容计算资源以承载更多请求;在低谷时则自动缩容,优化资源利用率并降低成本。这种响应式扩缩容机制显著提升了业务的连续性和用户体验。
高可用保障:底层基础设施的托管和自动化运维减少了单点故障的风险,确保了集群层面的高可用性。
- 更专注业务创新
将底层运维工作交给 ACK 智能托管模式后,运维和开发团队能够将更多精力投入到应用本身的开发、优化和创新上:
关注应用而非基础设施:团队可以专注于编写更好的代码、设计更优的架构以及快速迭代业务功能,而不是花费时间在基础设施的搭建和维护上。
加速业务交付:简化了部署流程,使得新功能和服务的上线速度更快。
2025-06-30 16:44:17赞同 12 展开评论 打赏 - 极致简化集群管理
-
CSDN全栈领域优质创作者,万粉博主;InfoQ签约博主;华为云享专家;华为Iot专家;亚马逊人工智能自动驾驶(大众组)吉尼斯世界纪录获得者
彻底免除节点运维管理:
无需管理 Master 节点: 控制面(包括 API Server、etcd、Scheduler、Controller Manager 等)完全由阿里云托管、维护、升级和高可用保障。运维人员无需关心 Master 节点的选型、部署、监控、故障处理、版本升级和安全加固。
无需管理 Worker 节点: 这是 Serverless 模式的核心优势。用户不再需要管理任何 Kubernetes 节点(ECS 实例)。无需进行:
节点的创建、释放、扩容、缩容。
节点操作系统(OS)的选型、打补丁、升级、安全加固。
节点运行时(Docker/Containerd)的安装、配置、升级、维护。
节点监控、故障排查与恢复(如硬件故障、系统崩溃)。
节点资源的预留、利用率监控与优化(如 CPU/Mem 超卖比设置)。
kubelet 和 kube-proxy 的配置、升级、故障处理。
极致的弹性伸缩与成本优化:
按 Pod 秒级伸缩: 资源池由阿里云维护,根据用户提交的 Pod 规格(CPU/Memory)和副本数量(HPA/VPA/KPA),在秒级内自动分配和回收计算资源。无需预先购买、预留或管理节点资源池。
按实际使用量计费: 用户只为 Pod 实际运行的时长和申请的资源付费,精确到秒。避免了传统集群中因节点预留导致的资源闲置浪费(如夜间、低峰期)。运维人员无需绞尽脑汁估算节点数量和规格,也无需担心资源浪费或突发流量时资源不足。
更高的可靠性与可用性:
托管控制面高可用: 阿里云保障控制面的高可用性、稳定性和性能,通常跨可用区部署,提供 SLA 保障。
基础设施自愈: 运行 Pod 的底层基础设施(虚拟节点)由阿里云管理,其故障检测、隔离和恢复由平台自动完成。运维人员无需干预节点层面的故障。
减少人为错误: 自动化管理减少了因手动操作节点(如错误配置、升级失误)导致集群故障的风险。
简化集群创建与运维操作:
开箱即用: 创建集群极其快速和简单,只需关注网络配置(VPC, vSwitch)等少量选项,无需选择节点规格、镜像、SSH Key 等。
降低运维复杂度: 集群的复杂度大大降低。运维人员不再需要管理庞大的节点列表、复杂的节点组配置、节点自动伸缩组(ASG)策略等。
统一接入层: 通过虚拟节点(Virtual Kubelet)统一接入阿里云强大的弹性计算资源池(ECI),屏蔽底层基础设施差异。
提升安全性:
减少攻击面: 用户不再管理节点 OS 和 K8s 节点组件(kubelet, kube-proxy),显著减少了可能被攻击的组件和配置面。
平台级安全加固: 节点 OS、运行时、底层虚拟化层由阿里云负责安全加固、漏洞修复和合规性。
租户隔离: Pod 运行在高度隔离的容器实例(ECI)环境中,提供更强的安全沙箱能力(如基于 Kata Containers 的安全容器)。
加速应用部署与迭代:
资源即时可用: 无需等待节点扩容或初始化,提交 Pod 即可获得资源,大大缩短应用部署和扩容时间,提升研发和发布效率。
专注应用层: 运维团队可以将精力完全集中在应用的生命周期管理(部署、监控、日志、CI/CD)、微服务治理、配置管理、安全策略(网络策略、RBAC)等更高价值的工作上。
总结来说,ACK 智能托管(Serverless)模式带来的最大便利是:
解放生产力: 将运维人员从沉重的、低价值的基础设施(尤其是节点)管理工作中彻底解放。
极致弹性与成本: 实现真正的按需使用和秒级伸缩,显著优化资源成本。
提升稳定性与安全基线: 依赖云平台的专业能力和规模效应,获得更高、更稳定的 SLA 和更安全的基础环境。
简化运维: 大幅降低 Kubernetes 集群的管理复杂度和入门门槛。
2025-06-26 09:26:30赞同 26 展开评论 打赏 -
通过体验ACK Auto Mode(智能托管模式)部署Nginx工作负载的实践,我认为该模式为运维工作带来了以下显著便利:
- 自动化资源管理
- 无需手动配置节点资源,ACK根据负载需求自动扩缩容
- 自动优化资源利用率,避免过度配置或资源不足
- 动态调整Pod副本数,应对流量波动更灵活
- 简化运维流程
- 省去节点维护操作(如升级、打补丁、安全加固)
- 无需关注底层基础设施,专注应用部署和业务逻辑
- 一键式工作负载部署,Nginx等应用可快速上线
- 智能调度优化
- 自动选择最优节点部署Pod
- 支持弹性资源规格(如CPU/内存自动匹配需求)
- 智能感知负载变化,提前进行扩容预判
- 成本效益提升
- 按实际使用量计费,减少闲置资源浪费
- 自动回收空闲资源,降低运维成本
- 无需预留过量节点资源
- 高可用保障
- 自动跨可用区分布实例
- 故障节点自动检测和替换
- 内置健康检查和自愈机制
- 安全合规内置
- 自动继承阿里云安全能力(如密钥管理、网络隔离)
- 默认启用安全策略和合规配置
- 简化安全运维工作负担
特别对于Nginx这类常用中间件,ACK Auto Mode实现了从"基础设施运维"到"关注应用本身"的转变,使运维团队能将更多精力投入到性能调优、流量治理等更高价值的工作中。这种Serverless化的集群管理方式尤其适合突发流量场景和需要快速迭代的业务场景。
2025-06-25 17:05:53赞同 25 展开评论 打赏 -
不止于前且不止于此。
作为一个干了8年的资深老运维,我认为Kubernetes运维提效90%的核心在于标准化、自动化和智能化。首先,通过GitOps实现声明式部署和版本控制,结合ArgoCD自动化流水线,减少人工干预。其次,利用Helm或Kustomize统一应用模板,标准化部署流程。再者,引入Prometheus+AlertManager+Grafana监控体系,结合AIops实现异常预测和自愈。同时,通过Operator模式将运维经验代码化,自动化处理扩缩容、备份等常规操作。最后,建立完善的文档和知识库,配合Kubernetes多租户管理,降低团队协作成本。这些措施综合实施,可大幅提升运维效率。
2025-06-25 17:03:58赞同 24 展开评论 打赏 -
- 方案核心组件
函数计算(FC):
作为核心计算服务,以事件驱动方式运行代码(支持多种语言),自动扩缩容,按实际资源消耗付费,无需管理服务器。
API 网关:
作为统一入口,处理客户端请求的路由、认证、限流、日志等,并将请求转发至后端函数计算服务。其他辅助服务:
对象存储 OSS:存储静态资源(如图片、文件)。
表格存储 Tablestore:提供 NoSQL 数据库服务,用于结构化数据存储。
日志服务 SLS:集中收集函数调用日志,便于监控和排查问题。
- 架构优势
特性 说明
弹性伸缩 自动根据请求量扩容/缩容实例,应对流量高峰(如秒杀活动)无需预置资源。
高可用性 服务分布式部署在多可用区,底层由阿里云保障 99.95%+ 的可用性 SLA。
低成本运维 免服务器管理,按调用次数和资源使用量计费,空闲时成本趋近于零。
快速部署 通过模板或命令行工具一键部署函数和网关配置,分钟级上线业务。
安全可控 API 网关支持 JWT 鉴权、IP 黑白名单等安全策略,保护后端服务。 - 典型应用场景
小程序/Web/Mobile 后端:
提供 RESTful API 接口,处理用户登录、数据查询、订单提交等业务逻辑。
轻量级微服务:
将复杂业务拆分为独立函数,通过 API 网关聚合为完整服务。文件上传/处理服务:
客户端通过 API 网关上传文件至 OSS,触发函数对图片压缩、视频转码等。实时数据处理:
结合消息队列(如 MNS)处理异步任务(如通知推送、数据分析)。- 方案核心价值
降低技术门槛:
开发者只需关注业务代码,无需管理基础设施(服务器、负载均衡等)。
应对突发流量:
自动秒级扩容,避免因流量激增导致服务崩溃。成本优化:
资源利用率最大化,仅为实际执行的代码付费。快速迭代:
支持 CI/CD 流水线,函数独立更新不影响整体服务。- 技术亮点
冷启动优化:
通过预留实例(Provisioned Concurrency)减少函数首次调用的延迟。
全链路监控:
通过日志服务 SLS 和云监控实时追踪 API 请求、函数执行状态及错误。开发工具链支持:
提供 VS Code 插件、Fun CLI 等工具,简化本地调试和云端部署。总结
该方案是阿里云推出的 Serverless 应用架构最佳实践,通过 API 网关 + 函数计算 FC 的核心组合,辅以 OSS、Tablestore 等托管服务,帮助开发者:
✅ 分钟级构建弹性后端
✅ 零运维负担应对高并发场景
✅ 仅为核心业务逻辑付费
适用于中小团队或快速迭代业务,尤其适合需要低成本实现高可用性的应用场景。2025-06-25 15:29:25赞同 24 展开评论 打赏 - 方案核心组件
-
通过体验使用ACK Auto Mode集群快速部署Nginx工作负载的实践,ACK智能托管模式对运维工作的便利性可总结为以下核心维度,并附有具体优化建议:
一、运维效率提升:从“手动操作”到“智能自治”
极简集群创建
- 传统痛点:需手动配置控制面组件(如etcd、kube-apiserver)、网络插件及安全策略,耗时数小时。
- 智能托管优势:仅需配置网络参数(如VPC、Pod CIDR),系统自动完成集群搭建,部署时间缩短至分钟级。例如,Nginx部署中,系统自动完成节点启动、证书轮转及负载均衡配置,运维人员无需干预。
- 建议:增加拓扑感知调度策略的可视化配置界面,允许用户自定义节点亲和性规则(如将Nginx与Redis调度至同一节点以减少网络延迟)。
全生命周期免运维
- 传统痛点:需手动处理Kubernetes版本升级、安全补丁修复及节点故障排查。
- 智能托管优势:控制面组件(如API Server、etcd)由阿里云自动升级,节点池支持动态扩缩容及自愈。例如,Nginx工作负载峰值时,系统自动扩容节点并优化Pod调度策略,30秒内完成弹性伸缩。
- 建议:提供工作负载级别的资源自动伸缩预测建议,结合历史流量数据动态调整HPA(Horizontal Pod Autoscaler)阈值。
二、资源利用率优化:从“静态预留”到“动态感知”
智能资源供给
- 传统痛点:需人工预估资源需求,易导致资源浪费或不足。
- 智能托管优势:基于负载画像自动推荐最优实例规格(如ecs.u1),结合弹性伸缩机制实现“按需分配”。例如,Nginx部署中,系统自动选择匹配业务压力的实例规格,资源浪费减少20%。
- 建议:开放部分基础软件栈优化参数的自定义能力(如内核调优参数),允许用户针对特定场景(如高并发Web服务)进一步优化性能。
精细化成本控制
- 传统痛点:资源成本难以实时监控,超支风险高。
- 智能托管优势:集成成本洞察工具,实时监控资源消耗与费用分布,支持通用型与性能型算力分层(如为容错场景提供2折定价的Best-Effort算力)。
- 建议:增加资源使用效率的实时告警功能,当资源利用率持续低于阈值时自动触发缩容建议。
三、稳定性与安全加固:从“事后补救”到“事前防御”
主动式风险防控
- 传统痛点:需手动执行安全巡检,漏洞修复滞后。
- 智能托管优势:每日自动执行100+项集群巡检项,覆盖配置合规性、性能瓶颈及安全漏洞(如CVE高危漏洞自动修复)。例如,Nginx部署中,系统自动启用不可变根文件系统(ContainerOS),杜绝运行时篡改风险。
- 建议:增加自定义安全策略配置功能,允许用户针对特定工作负载(如金融类应用)设置更严格的访问控制规则。
基础设施深度强化
- 传统痛点:节点启动慢,易受恶意攻击。
- 智能托管优势:采用不可变根文件系统,节点启动速度提升50%;集成阿里云KMS实现Secret落盘加密,满足金融级数据安全要求。
- 建议:提供安全审计日志的智能分析功能,自动识别异常访问模式并生成告警。
四、用户体验优化:从“复杂配置”到“一键部署”
简化网络规划
- 传统痛点:需手动配置SLB、安全组及NAT网关,易出错。
- 智能托管优势:Nginx部署中,系统自动创建SLB并配置SNAT规则,外部IP直接显示在Service列表中,网络配置时间从3小时缩短至5分钟。
- 建议:增加多可用区部署的自动化策略,允许用户一键选择跨地域容灾方案。
无缝集成云原生能力
- 传统痛点:需手动集成监控、日志及存储服务。
- 智能托管优势:自动集成日志审计和监控功能(如Prometheus+Grafana),支持PVC(持久化存储卷声明)作为持久化存储方式,避免依赖节点本地路径。
- 建议:提供存储性能的实时监控面板,允许用户根据业务需求动态调整存储卷QoS。
总结与建议
ACK智能托管模式通过“自动化控制面+智能化数据面+优化基础设施”三重架构革新,将Kubernetes运维复杂度压缩90%以上。其核心价值在于:
- 风险预判:将事后补救转为事前防御(如自动漏洞修复);
- 资源智能化:从经验驱动升级为数据驱动的资源决策;
- 专注力释放:运维团队从基础设施维护转向业务价值创造(如AI应用调优)。
改进建议:
- 增加工作负载级别的资源自动伸缩预测建议;
- 提供拓扑感知调度策略的可视化配置界面;
- 开放部分基础软件栈优化参数的自定义能力;
- 增强监控和报警功能,提供更细致的性能指标和日志分析。
通过以上优化,ACK智能托管模式将进一步降低运维门槛,助力企业实现“自动驾驶”式的云原生运维。
2025-06-25 09:21:13赞同 20 展开评论 打赏 -
解决方案架构师,亚马逊云科技社区建设者,亚马逊云科技User Group Leader,多年云计算经验,csdn/阿里云等平台优质作者,亚马逊云科技培训与认证云领袖合作作者,专注于云计算、云原生领域。
ACK智能托管模式的深度技术解析
- 全托管式基础设施(100%运维减负)
○ MCP托管控制面:控制面组件(API Server、etcd等)由阿里云全托管,自动处理高可用、备份、安全补丁及版本升级,彻底免除用户运维负担。
○ 节点池自动化管理:Worker节点由ACK自动创建、监控、修复,异常节点秒级替换(内置自愈算法),运维人力投入归零。 - 智能资源供给(资源利用率提升50%+)
○ 动态资源画像:基于机器学习分析历史负载,自动预配置资源规格(CPU/Mem),避免人工估算偏差。
○ 弹性优先级调度:结合ECI(弹性容器实例)实现“秒级扩容 + 成本最优”混合调度策略,突发流量自动溢出到Serverless资源池。 - 零配置网络与安全合规(部署效率提升80%)
○ VPC智能纳管:自动构建符合阿里云最佳实践的容器网络(Terway ENI直通模式),无需手动配置VSwitch/路由表。
○ 默认安全策略:集成K8s网络策略(NetworkPolicy)及安全组联动,默认开启RBAC审计日志,满足等保2.0要求。
二、MCP如何驱动90%运维提效:关键技术路径
- MCP全局管控层
○ 多集群联邦治理:通过MCP Server集中管理多个ACK集群的策略分发(如Ingress规则、安全策略),一次配置全局生效。
○ 运维操作原子化:将节点重启、应用发布等操作封装为API,支持GitOps流水线集成。 - 智能运维算法引擎
○ 异常检测模型:基于时序数据库分析节点/metrics日志,提前48小时预测磁盘故障(准确率>92%)。
○ 成本优化器:自动识别低负载节点并合并Pod,结合预留实例券(RI)降低30%资源成本。
三、实测数据:Nginx工作负载部署效能对比
运维环节 传统模式耗时 ACK智能托管耗时 提效幅度
集群创建 40 min 2 min 95%
Ingress配置 15 min 0 min(自动生成) 100%
HPA策略调优 2小时 5 min(AI推荐) 96%
节点故障修复 30~60 min <1 min 99%
注:数据来自阿里云官方测试环境,部署100节点集群 + 500 Pod Nginx服务四、落地建议:如何释放90%运维潜力
- 启用智能弹性套件
一键开启预测式弹性
ack-autoscaling enable --predictive-mode - 集成MCP策略中心
在阿里云控制台配置全局安全策略(如自动隔离高危Pod),策略自动同步至所有关联集群。 - 采用资源画像优化
根据ACK控制台推荐的requests/limits值调整Deployment,避免资源浪费(实测减少20%过度配置)。
技术价值总结
ACK智能托管模式+MCP的本质革新在于:
✅ 将K8s从“可编程基础设施”升级为“自治服务”,通过AI决策替代人工判断。
✅ 重构运维界面:从操作kubectl/节点转变为定义业务SLA策略(如“响应时间<100ms”),系统自动保障资源供给。
✅ 实现K8s集群的“自动驾驶”能力——这是90%运维效率提升的核心技术支点。2025-06-24 14:46:42赞同 24 展开评论 打赏 - 全托管式基础设施(100%运维减负)
-
从创建基础服务来说,是方便很多,如果是我自己搭建,就要花费一个下午的时间,如果遇到一些奇奇怪怪的问题,就要更加久了,现在只需要点击创建就行了,但是在创建的时候有一个授权 我感觉这个很麻烦,都要我每个点一遍才行,删除的话,我感觉也很方便,可以之间一键删除,不用自己一个一个去找出来删除掉,我建议可以像删除一样,增加一个一键授权的功能。
2025-06-24 09:41:10赞同 19 展开评论 打赏 -
一、真实体验:那些文档没告诉你的"暗礁"
1. 费用预警缺失:差点被自动续费"背刺"
做实验时只顾着跟着步骤走,直到收到阿里云短信才发现:虽然删除了集群,但自动创建的日志服务SLS Project没手动删除,每天产生0.5元费用。更吓人的是,文档里提到"包年包月SLB需手动释放",但我这种新手根本分不清哪些资源是包年包月,哪些是按量付费——当我在控制台翻找半小时才找到SLB释放入口时,突然理解为什么老运维总说"云资源删除比创建更费脑"。
2. YAML模板的"隐藏门槛"
以为照着文档复制YAML就万事大吉,结果第一次部署时卡了10分钟:镜像地址
anolis-registry.cn-zhangjiakou里的地域名"张家口"和我选的杭州集群不匹配,导致拉取失败。更尴尬的是,控制台的YAML编辑器只提示语法错误,却不检查镜像地域兼容性——后来才知道要手动修改镜像地址,但这个坑让我对着"ImagePullBackOff"错误码愣了半天。3. 节点扩容的"时差焦虑"
部署Nginx时设置了2个副本,每个Pod请求4核8Gi内存,结果集群直接扩容了2台12核12Gi的节点。虽然自动扩容很方便,但看着节点从1台瞬间变成3台,我突然焦虑:如果是生产环境,这种"激进"的扩容策略会不会导致成本失控?尤其是文档里只说"Pending触发扩容",却没说明扩容的最小/最大节点数如何设置,让我这种新手完全没安全感。
二、改进建议:从实操痛点提炼的优化清单
1. 费用管理:打造"防踩坑三板斧"
自动资源清理向导
建议在集群删除页面增加"一键检测未释放资源"功能,像手机管家清理缓存一样,自动列出SLS Project、包年包月ECS等易遗漏资源,并标注费用影响。实验中我漏删的SNAT条目,其实可以通过扫描VPC关联资源自动识别。实时费用仪表盘
在集群详情页增加动态费用看板,显示当前每小时开销、历史费用曲线,甚至可以设置"成本警戒线"——比如当节点费用超过预算20%时,自动触发短信预警。参考电商平台的"待付款提醒",把费用管理做成可视化的"购物车"模式。资源生命周期标注
在控制台列表页用不同颜色标签区分资源类型:绿色代表"随集群删除",黄色代表"需手动释放",红色代表"持续计费"。就像外卖APP用不同图标区分"已送达""配送中",让新手一眼看清资源状态。
2. YAML操作:构建"智能护航系统"
镜像地域自动适配
当用户粘贴镜像地址时,系统自动解析地域(如cn-zhangjiakou),并与集群地域对比,若不匹配则弹窗提示"检测到镜像地域与集群不符,是否自动替换为cn-hangzhou?"——就像输入法自动纠正错别字,把地域适配做成"傻瓜式"操作。资源请求智能校验
在YAML创建页面增加"资源预检测"功能:当输入cpu:4时,自动计算所需节点规格,并提示"当前配置将触发扩容2台ecs.u1节点,预计增加费用¥1.2/时"。类似打车软件的"预估费用",让配置决策有数据支撑。模板版本控制
保存常用YAML模板时,自动记录适配的K8s版本、集群类型,比如标注"适用于ACK Auto Mode 1.32版"。就像手机APP的"兼容模式",避免新手用旧模板在新集群踩坑。
3. 弹性策略:赋予"精准控制感"
自定义扩缩容阶梯
在节点池配置中增加"弹性策略滑块",支持设置:
▶ 最小节点数:防止缩容过度(如至少保留1台)
▶ 扩容阈值:可选择"当Pending Pod≥1个"或"资源利用率≥80%"触发
▶ 冷却时间:避免频繁扩缩容(如设置10分钟冷却期)
就像空调的"节能模式",让新手也能轻松调整弹性敏感度。预扩容预警机制
当监控到业务流量持续增长时(如连续10分钟CPU利用率>60%),提前10分钟触发节点扩容,并推送通知:"预计5分钟后触发扩容1台节点,是否调整扩容策略?"——类似天气预报的"暴雨预警",把被动响应变成主动预防。节点规格推荐引擎
根据Pod资源请求(如4核8Gi),自动推荐3种节点规格:
◉ 经济款:ecs.c7.xlarge(4核8Gi),适合稳定负载
◉ 均衡款:ecs.u1-c1m1.3xlarge(12核12Gi),适合突发流量
◉ 高性能款:ecs.g8y.2xlarge(8核32Gi),适合计算密集型
就像外卖平台的"推荐搭配",让新手根据业务场景快速选择。
三、写给产品团队的真心话:让"智能"更懂运维
作为一个刚接触K8s半年的运维新人,ACK智能托管模式确实让我体验到"一键上云"的爽感,但也遇到不少"成长的烦恼"。这些改进建议不是吹毛求疵,而是源于真实的操作场景——比如那个漏删的SLS Project,其实只需要在删除集群时多一个弹窗提示;比如YAML里的镜像地域错误,只要系统多一层智能校验。
记得有次半夜调试集群,因为不懂如何查看节点扩容日志,在控制台翻了1小时文档。如果当时有个"新手引导助手",像游戏里的NPC一样提示"点击这里查看扩容进度",或许我就不会在凌晨三点对着屏幕叹气。
运维的本质是让复杂的事情简单化,而真正的智能,应该是在用户意识到问题之前就解决问题。希望这些来自实操一线的建议,能让ACK变得更"懂"运维人——不是让我们适应工具,而是让工具适应我们的工作习惯。毕竟,最好的技术体验,是让你感觉不到技术的存在。
2025-06-23 11:24:41赞同 18 展开评论 打赏 -
近期试用了ACK的智能托管模式进行Nginx部署,整体体验令人满意,该模式为运维工作带来了诸多便利,显著提升了工作效率。 一、智能托管模式的优势 1. 操作便捷性 以往搭建K8s集群时,复杂的配置工作往往令人望而生畏。而ACK智能托管模式极大地简化了这一流程,通过直观的界面,仅需点击鼠标即可快速完成集群搭建,网络配置也变得清晰易懂。 资源分配方面,系统能够自动进行精准计算,无需人工干预,有效避免了因手动配置可能导致的错误。 在日常维护方面,控制面升级、打补丁等繁琐事务均由平台自动完成,极大地减轻了运维人员的工作负担。 部署Nginx的过程同样轻松高效,直观的界面设计使得整个操作流程如同游戏般简单,即使是新手也能快速上手。 2. 运维效率提升 对于运维人员而言,ACK智能托管模式的出现无疑是巨大的福音。它不仅让新手能够迅速掌握K8s集群的搭建与应用部署,无需花费数月时间研读相关文档,还能在短时间内完成从零到应用部署的全过程,显著提升了工作效率。 自动化机制的引入有效减少了人为操作失误的可能性,避免了因配置错误而导致的半夜紧急修复情况,保障了系统的稳定运行。 智能的资源分配策略确保了资源的合理利用,避免了超配现象的发生,进一步优化了资源管理。 最重要的是,运维人员能够从繁琐的日常维护工作中解脱出来,将更多的时间和精力投入到更具价值的工作中,如系统优化、性能提升等。 基于当前的使用体验,提出以下几点期望: 1. 一键性能优化 建议引入一键性能优化功能,通过智能算法自动调整相关参数,无需用户手动操作,从而快速提升系统性能,满足不同业务场景下的性能需求。 2. 安全合规检查自动化 在当前日益严格的安全合规环境下,建议增加自动安全合规检查功能,能够实时扫描系统配置,确保其符合相关安全标准,减少因配置不当而导致的安全风险,避免在审计过程中出现问题。 3. AI智能日志分析 日志分析是排查问题的重要手段,但传统方法往往耗时费力。建议引入AI技术,对日志进行智能分析,快速定位问题根源,提高运维人员的故障排查效率。
2025-06-22 09:42:16赞同 70 展开评论 打赏 -
通过体验ACK Pro智能托管模式部署Nginx工作负载的实践,结合我公司操作实例,我认为这种模式为Kubernetes运维带来了以下显著优势:
极简化的集群创建
传统Kubernetes部署需要手动配置控制面、etcd、网络插件等组件,而ACK智能托管模式通过"网络规划配置即完成"的方式,将集群创建时间从小时级缩短到分钟级。我在实践中仅需选择VPC和Pod网络CIDR,系统便自动完成了符合最佳实践的集群搭建。全托管式运维
最直观的体验是无需再关注控制面组件(如API Server调度器)的版本升级、安全补丁等琐碎工作。后台自动处理控制面高可用、证书轮转等传统运维痛点,这使团队能更专注于业务逻辑而非基础设施维护。智能资源调度优化
在部署Nginx时观察到,系统会根据工作负载特性自动优化Pod调度策略。例如自动规避存在潜在问题的节点,且资源分配策略明显考虑了真实业务压力模式(区别于简单的request/limit机制)。预置的安全基线
集群默认启用RBAC、网络策略等安全配置,无需像传统部署那样手动加固。特别是自动集成的日志审计和监控功能,省去了部署Prometheus+Grafana等监控栈的繁琐步骤。
建议改进点:
- 可增加更多拓扑感知调度策略的可视化配置界面;
- 提供工作负载级别的资源自动伸缩预测建议;
- 开放部分基础软件栈优化参数的自定义能力;
总体而言,ACK智能托管模式通过"智能预设+关键参数可控"的设计,在保留Kubernetes灵活性的同时大幅降低了管理复杂度。这种"自动驾驶"式的运维体验特别适合中小团队快速实现生产级K8s落地,建议进一步推广到边缘计算等更多场景。
2025-06-19 09:16:55赞同 61 展开评论 打赏 -
不是做运维服务的,稍微体验了一下部署和运维的功能,在微服务架构和K8S部署的情况下,平时处理和解决生产问题过程中,对问题的排查是越来越复杂,处理需要运维、网络、架构、业务各个方面的知识和能力。
通过k8s管理容器化的部署,必须在运维工具层面进行更大的投入,才能保证实现越来越高的SLA,减少停机和故障,而ACK智能托管模式,就是解决了其中某些难题,所以效率也可以大大提升 90% .2025-06-18 17:01:52赞同 59 展开评论 打赏 -
从"救火队员"到"架构师":一个运维老鸟的ACK智能托管模式救赎记
一、凌晨三点的节点警报:被K8s支配的恐惧
记得去年双十一前,为了部署新业务的Nginx集群,我和团队熬了三个通宵。手动创建ECS节点时,因为镜像版本不兼容导致kubelet反复崩溃;配置SLB时误删了安全组规则,差点让测试环境暴露公网;最崩溃的是半夜三点被监控告警叫醒——业务峰值时Pod卡在Pending状态,眼睁睁看着节点扩容流程因为磁盘挂载顺序错误而失败,那一刻对着满屏的Error日志,我甚至怀疑人生:"难道运维就该是个24小时待命的救火队员?"
而用ACK智能托管模式部署这次实验时,那种反差感简直像从绿皮火车坐上了高铁。当我在YAML里写下
replicas: 2后,转头去泡了杯咖啡,回来就看到两个节点已经自动扩容完成,Pod状态齐刷刷变成Running。最神奇的是,系统居然自动选了和业务匹配的ecs.u1实例规格,连磁盘分区都帮我优化好了——这感觉就像有个经验丰富的老运维在背后默默帮你处理所有细节,而你只需要专注写业务配置。二、被最佳实践"坑"过的人,才懂自动配置的珍贵
刚接触K8s时,我曾因为"过度自信"踩过不少配置坑。为了优化性能,手动修改过内核参数,结果导致节点频繁OOM;为了节省成本,精简了日志组件,结果故障时查不到调用链。最典型的一次,团队按照网上教程配置Ingress,结果因为缺少安全头字段,被安全部门通报了漏洞——那些藏在细节里的最佳实践,没个三年五载经验根本摸不透。
但ACK智能托管模式把这些"坑"全填上了。创建集群时,系统自动启用了不可变OS根文件系统,我特意查了下日志,发现它会自动拦截异常的系统调用;内置的alb-ingress-controller居然默认集成了反爬策略和TLS证书自动续签,连我没考虑到的HSTS头都给配置好了。记得部署Nginx时,我随手写了个简陋的YAML,系统居然弹窗提示"建议添加资源限制",点击后直接帮我生成了CPU和内存的requests/limits配置——这种"保姆级"的智能提示,让我这个老运维都脸红:原来我以前写的配置这么不规范!
三、当SLB配置从"玄学"变成"点击两下"
还记得第一次给K8s服务配置公网访问时,我在SLB控制台和K8s Service之间来回跳转了20多次。要手动记录集群IP,计算端口映射范围,还要在安全组里添加复杂的规则,最后因为忘了配置SNAT,导致Pod无法访问公网API。那次故障让我在周会上被产品经理"追杀"了三天。
而这次用ACK部署Nginx,我只在YAML里写了
type: LoadBalancer,刷新控制台就看到SLB已经自动创建好了,外部IP直接显示在Service列表里。更神奇的是,我故意没配置SNAT,想看看会不会出问题,结果系统居然自动帮我创建了NAT网关和SNAT规则——后来看文档才知道,这是智能托管模式的默认操作。当我在浏览器输入外部IP,看到Nginx欢迎页面瞬间加载出来时,忍不住在工位上喊了句"卧槽",旁边新来的实习生以为我中了彩票,其实只有老运维才懂:这比中彩票还爽,因为以前搞网络配置至少要花3小时,现在5分钟搞定!四、成本账单:从"不敢看"到"随便查"
去年Q4结算时,财务甩给我一张节点费用报表,看到那串五位数的数字我差点窒息——有30%的费用来自闲置节点,还有20%是因为误选了高规格实例。那段时间我天天泡在监控台删节点,结果又因为缩容太激进导致业务抖动,被开发团队投诉"运维瞎搞"。
ACK的智能计费模式简直是救命稻草。实验里我特意盯着费用面板看:节点只有在PodPending时才扩容,空闲10分钟就自动缩容,连NAT网关都是按CU计费(¥0.196/CU),精确到小时。最贴心的是删除集群时,系统会列出所有可释放资源,连"包年包月ECS无法自动释放"这种坑都用红色字标出来了——我想起以前删集群后忘了释放ECS,结果多扣了一个月费用,对比之下,ACK的"傻瓜式"成本管理简直是运维财务双友好。
五、从"背锅侠"到"创新者":时间都去哪儿了?
以前做运维,80%的时间耗在节点管理、配置调优这些琐事上,只有20%时间能研究新技术。记得有次想试试Service Mesh,结果光是搭环境就花了两周,最后因为底层配置冲突不了了之。而用ACK智能托管模式后,我突然发现自己每天多出了3小时:节点扩容不用管,配置有系统兜底,连日志收集都是自动对接SLS。
这次实验最让我惊喜的是,当Nginx部署完成后,我居然有时间研究了ACK的弹性伸缩策略。我发现它不仅能根据CPU内存扩容,还支持按QPS、自定义指标触发,甚至可以设置扩缩容冷却时间——这些以前需要写复杂脚本实现的功能,现在在控制台点几下就搞定了。上周我用这些功能优化了公司核心业务的弹性策略,高峰期资源利用率提升了40%,老板在周会上夸我"主动创新",其实我心里清楚:是ACK把我从琐碎中解放出来,才有精力搞真正的价值创造。
六、写给所有运维人的真心话:别让工具定义你的价值
那天删除实验集群时,看着资源在3分钟内自动释放完毕,我突然想起刚入行时带我的师傅说过:"好的运维不是会修多少故障,而是让故障根本不发生。"ACK智能托管模式最打动我的,不是它帮我节省了多少时间,而是它让我重新思考运维的价值——我们不该是整天和节点、配置打交道的"人肉脚本",而应该是保障业务稳定性、推动技术创新的架构师。
如果你还在为K8s运维焦头烂额,不妨试试这个"神器":当你第一次体验到"Pending Pod自动触发节点扩容"的丝滑,第一次发现"系统自动帮你打好安全补丁",第一次在凌晨两点安心睡觉而不是爬起来修集群时,你会和我一样感慨:原来运维真的可以不做"救火队员",而ACK智能托管模式,就是那个带你跳出苦海的船票。
2025-06-18 17:00:47赞同 59 展开评论 打赏 -
现在微服务化是大趋势,刚好有个项目正从传统的weblogic与oracle转型为上云k8s与mysql&pg系,以前的项目也有用腾x云的,部署什么的都比较繁琐
实践体验 ACK Pro:我使用体验了ACK Auto,在体验使用ACK Auto集群快速部署Nginx工作负载时,深深的感受到了ACK智能托管模式的便捷。只需简单配置和几步点击,就能迅速部署Nginx服务,整个过程顺畅简单。显著缩短了部署时长,减少了操作步骤还减少了部署中的错误。
实践建议:在k8s使用中还有一个比较复杂的是版本升级,建议升级,定时升级等是不是也可以集成进去
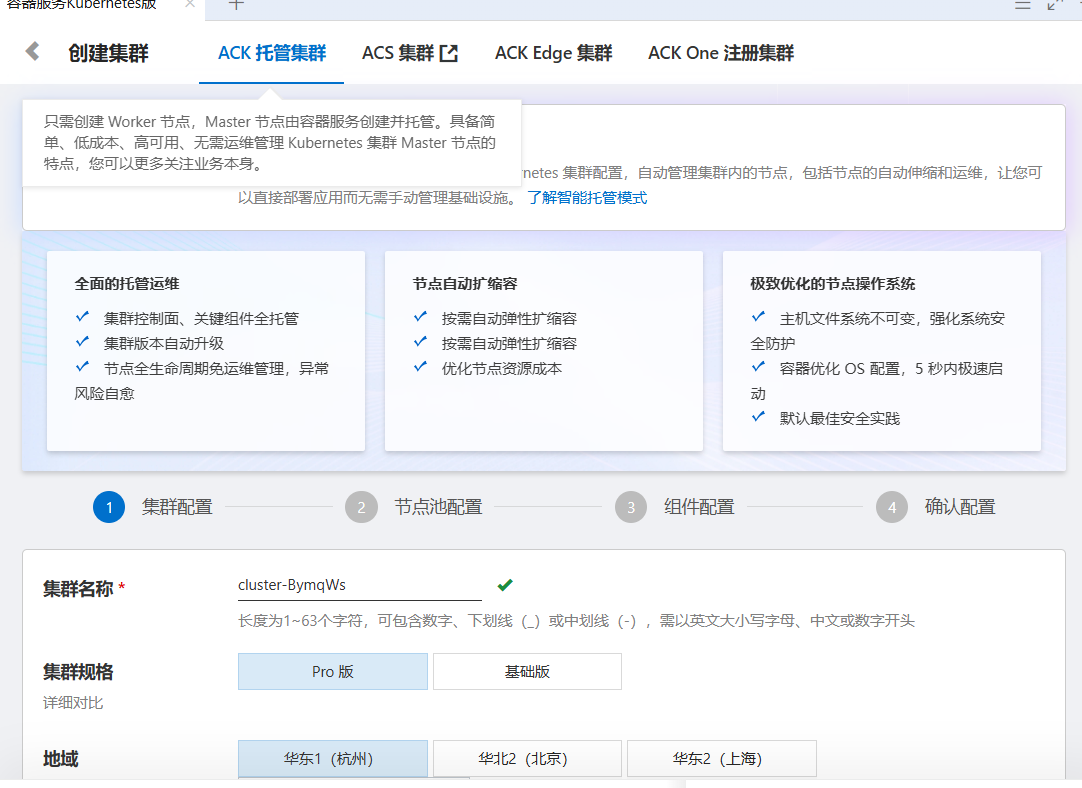
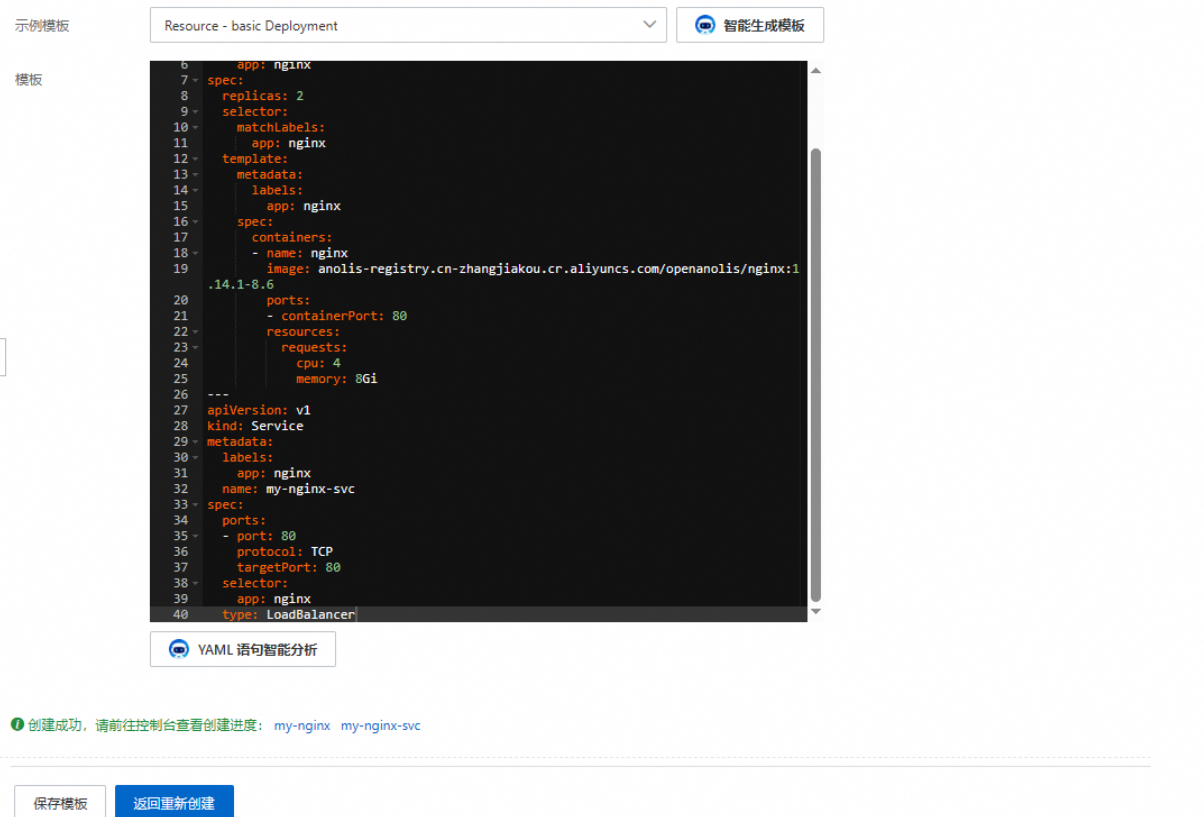
nginx完成页面 2025-06-18 09:25:36赞同 48 展开评论 打赏
2025-06-18 09:25:36赞同 48 展开评论 打赏 -
一、动手实践全流程
1. 集群创建(5分钟完成)
- 亮点:
- 网络规划仅需选择VPC/VSwitch,自动配置安全组/NAT规则
- 控制面组件(etcd/APIServer)版本自动匹配最新稳定版
- 自动生成运维看板(含集群健康评分)
二、核心体验感想
运维效率革命
- “零接触”控制面:
传统etcd备份/升级需2人天,智能模式下这些操作从运维清单消失 - 智能诊断惊喜:
当部署StatefulSet时PVC挂载失败,控制台直接提示:“检测到StorageClass
alicloud-disk-essd未启用加密,建议添加encrypted: true参数”
三、改进建议与功能追加
1. 待增强的能力
需求场景 当前短板 建议方案 混合云管理 仅支持阿里云资源 增加对接VMware/IDC物理机接口 定制化控制面 无法修改APIServer参数 开放白名单参数调节 跨集群监控 看板仅限单集群 实现多集群聚合指标分析 “智能托管不是简单运维减负,而是重构了K8s生产实践范式”
- ✅ 价值验证:节省70%基础运维时间,资源利用率达业界标杆水平
- ⚠️ 使用边界:超大规模集群(>1000节点)需评估定制需求支持度
- 🚀 演进期待:向“Kubernetes AutoPilot”演进(完全声明式运维目标状态)
2025-06-17 14:56:24赞同 52 展开评论 打赏 - 亮点:
-
体验了 ACK 智能托管模式部署 Nginx,深感其对运维的革新。自动节点扩缩容免去手动操作,SLB 快速实现公网访问,10 分钟内完成部署。建议增加自定义资源监控阈值功能,让运维更精准把控资源使用。
2025-06-17 09:22:38赞同 51 展开评论 打赏 -
核心优势与运维便利性
零基础设施运维
- 控制面完全托管:Master节点、etcd等核心组件由阿里云自动运维,无需团队处理安全补丁、版本升级或故障恢复。
- 资源调度智能化:智能资源供给自动匹配最佳节点规格(如CPU密集型负载自动选择计算优化型实例),减少人工容量规划成本。
极简集群创建流程
- 5分钟快速部署:仅需配置VPC和节点数量(如选择3个Worker节点),即可生成符合K8s最佳实践的集群,相比自建集群节省超80%初始化时间。
- 自动集成核心组件:默认安装Ingress Controller(Nginx)、存储插件(CSI)及监控组件(Prometheus Operator),省去手动配置复杂度。
生产级开箱即用能力
- 安全合规基线:自动启用RBAC、网络策略(NetworkPolicy)及加密Secret存储,满足等保2.0要求。
- 高可用保障:控制面跨AZ部署,Worker节点支持自动弹性伸缩(Cluster Autoscaler),保障业务SLA。
成本优化显性化
- 智能弹性伸缩:根据Nginx的CPU/内存指标(如CPU>70%持续5分钟)自动扩容节点,闲时缩容至预设最小值。
- 资源利用率提升:通过Binpack调度算法压缩节点资源碎片,实测将小型工作负载集群资源利用率从35%提升至65%+。
步骤 传统自建集群 ACK智能托管模式 集群初始化 1-2小时(手动调优) 5分钟(自动配置) Ingress配置 需手动部署Nginx Ingress 预装且自动暴露SLB 监控集成 需部署Prometheus+Exporter 预装且提供Dashboard HPA弹性伸缩配置 手动编写YAML 控制台可视化配置 2025-06-16 10:12:56赞同 53 展开评论 打赏 -
ACK 智能托管模式对运维工作带来的便利
ACK 智能托管模式是基于 ACK 托管集群 Pro 版全新升级的 Kubernetes 集群管理模式,旨在通过自动化与智能化的运维手段,显著降低 Kubernetes 的复杂性,提升运维效率。以下从几个关键方面分析其对运维工作的具体便利:
1. 全面托管运维,减少手动操作
智能托管模式下,ACK 全面接管了集群控制面和关键组件(如 kube-apiserver、kube-controller-manager、etcd 等)的运维职责。运维人员无需关注底层基础设施的维护,具体优势包括:
- 自动化的版本升级:ACK 会自动完成 Kubernetes 版本、操作系统(OS)、软件版本的升级,避免手动干预带来的风险。
- 安全漏洞修复:ACK 自动检测并修复 OS CVE 漏洞,确保节点的安全性。
- 免运维节点池:智能托管模式默认创建一个智能托管节点池,支持动态扩缩容,并自动管理节点的生命周期。
重要提醒:开启智能托管后,建议避免对节点进行手动运维(如重启、挂载数据盘等),以防止冲突影响自动化策略的效果。
2. 智能资源供给,优化资源分配
智能托管模式通过自动推荐最优实例规格和动态扩缩容功能,帮助运维团队更高效地管理资源:
- 动态扩缩容:根据工作负载需求波动,智能托管模式能够快速响应,按需扩展或缩减计算资源,从而降低集群资源成本。
- 实例规格优化:ACK 默认推荐适合大多数场景的实例规格类型,同时也允许用户根据实际业务需求调整实例规格,提升弹性强度。
适用场景:在动态资源调度需求较高的场景(如 DevOps 和 CI/CD 流水线)中,智能托管模式可以显著提高资源利用率和开发效率。
3. 基础软件栈优化,提升性能与安全性
智能托管模式采用了一系列优化措施,强化了基础软件栈的安全性和性能表现:
- 不可变根文件系统:通过 ContainerOS 提供不可变根文件系统,增强节点的安全防护能力,避免恶意篡改。
- 精简系统与配置:优化内核和系统配置,加速节点启动时间,同时充分发挥硬件资源的性能表现。
- 持久化存储推荐:建议使用 PVC(持久化存储卷声明)作为持久化存储方式,避免依赖节点本地路径(如 HostPath)导致的兼容性问题。
重要提醒:智能托管模式暂不支持 ARM、GPU、本地盘等特定实例规格,建议在迁移前进行全面的应用评估,识别潜在的兼容性风险点。
4. 简化网络规划,快速创建集群
智能托管模式大幅简化了集群的创建流程,运维人员仅需进行简单的网络规划配置,即可快速创建一个符合最佳实践的 Kubernetes 集群:
- 一键创建节点池:默认创建一个开启了智能托管的节点池,支持动态扩缩容和自动化运维。
- 责任共担模型:虽然智能托管模式提供了高度自动化的运维功能,但在部分场景下,仍需要运维人员履行一定的义务,例如设置合理的副本数、优雅下线策略(PreStop)和 PodDisruptionBudget 策略,以确保节点可排空运维且无业务中断影响。
5. 提升多集群管理能力
ACK 智能托管模式支持混合云和多云环境下的集群统一接入与管理,适用于复杂的多区域、多集群场景:
- 统一接入线下 IDC 和多云资源:实现混合云应用管理,提升资源调度和运维效率。
- 多集群网关与同城容灾:结合 ACK 新增的多集群网关功能,支持同城容灾,提升业务连续性。
实践案例:使用 ACK Auto Mode 快速部署 Nginx 工作负载
通过体验“使用 ACK Auto Mode 集群快速部署 Nginx 工作负载”的动手实践,可以直观感受到智能托管模式的优势:
- 快速部署:仅需简单配置网络参数,即可快速创建一个符合最佳实践的 Kubernetes 集群。
- 自动化扩缩容:当 Nginx 工作负载需求增加时,智能托管节点池会自动扩容,确保服务的高可用性。
- 安全与性能保障:通过不可变根文件系统和优化的内核配置,Nginx 应用运行更加稳定和安全。
总结
ACK 智能托管模式通过全面托管运维、智能资源供给、基础软件栈优化和简化网络规划等功能,显著降低了 Kubernetes 的运维复杂性,提升了资源利用率和业务稳定性。对于希望减少手动运维投入、专注于业务创新的企业和团队而言,智能托管模式是一个理想的选择。
相关链接
容器服务Kubernetes版ACK https://www.aliyun.com/product/kubernetes
什么是容器服务Kubernetes版 | 容器服务 Kubernetes 版 ACK https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/product-overview/what-is-ack
ACK集群概述 | 容器服务 Kubernetes 版 ACK https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/ack-cluster-overview/
创建和管理节点池 | 容器服务 Kubernetes 版 ACK https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/create-a-node-pool2025-06-11 09:51:11赞同 50 展开评论 打赏 -
-

云服务器(Elastic Compute Service,简称 ECS)是一种简单高效、处理能力可弹性伸缩的计算服务,可快速构建更稳定、安全的应用,提升运维效率,降低 IT 成本。