Discover, Discuss, and Read arXiv papers


Discover new, recommended papers

30 Jul 2025
This survey from a large collaborative group, including Princeton AI Lab, provides the first systematic and comprehensive review focusing on self-evolving agents, proposing a unified theoretical framework to categorize their mechanisms and temporalities. It distinguishes self-evolving agents from related AI paradigms and outlines critical research challenges and evaluation methodologies necessary for their advancement towards artificial super intelligence.

30 Jul 2025
Meta CLIP 2 from FAIR (Meta AI Research) presents a comprehensive recipe for training Contrastive Language-Image Pretraining (CLIP) models using worldwide, web-scale image-text data. This approach effectively breaks the 'curse of multilinguality,' demonstrating that non-English data can enhance English performance (e.g., ViT-H/14 ImageNet accuracy improved from 80.5% to 81.3%) while setting new state-of-the-art results on numerous multilingual benchmarks.

29 Jul 2025
Researchers at Anthropic introduce an automated pipeline for extracting "persona vectors" from large language models' activation spaces, enabling both the monitoring and causal control of character traits. They demonstrate that these vectors can prevent undesirable persona shifts during finetuning and effectively screen training data to predict and mitigate the induction of negative traits like evil, sycophancy, or hallucination.

31 Jul 2025
CoT-Self-Instruct, developed by FAIR at Meta, introduces a method for generating high-quality synthetic data for Large Language Models by combining Chain-of-Thought reasoning for instruction creation with robust, automated filtering mechanisms. This approach enables models trained on the synthetic data to achieve superior performance on both reasoning and general instruction-following benchmarks, often surpassing existing synthetic methods and human-annotated datasets.
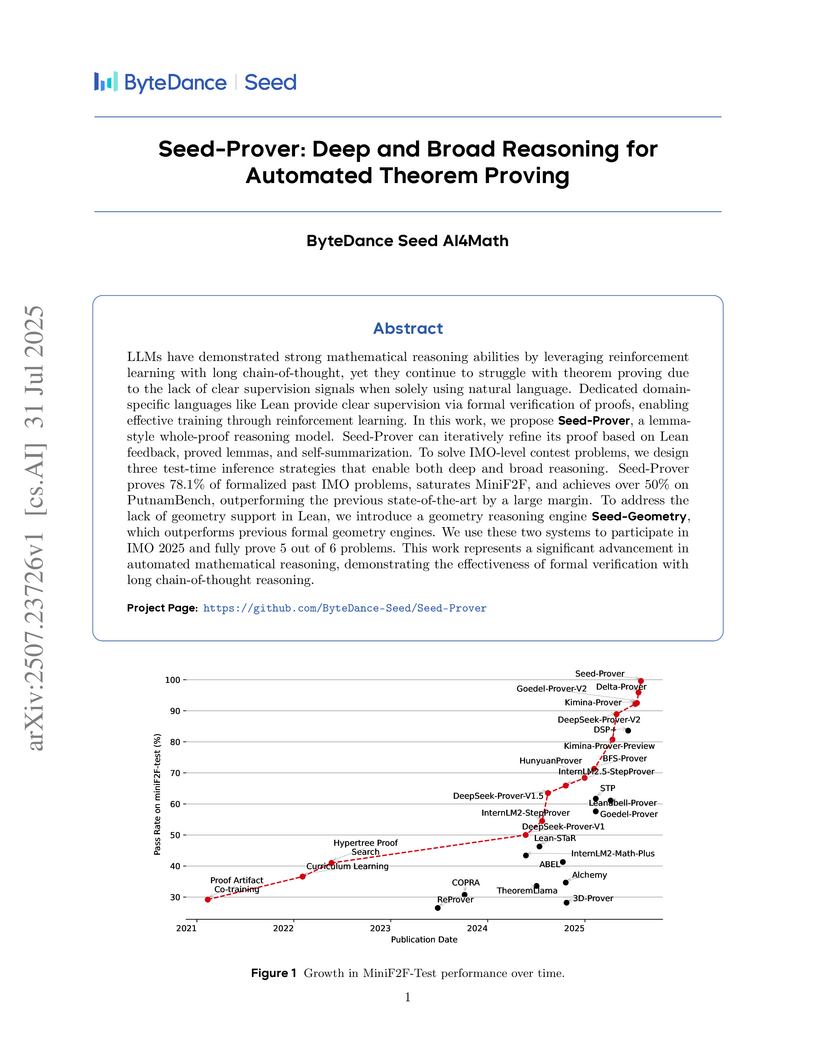
31 Jul 2025
ByteDance Seed AI4Math's Seed-Prover and Seed-Geometry are AI systems that successfully proved 5 out of 6 problems in the IMO 2025 competition, establishing new state-of-the-art results across several formal mathematical benchmarks including MiniF2F and PutnamBench. The systems achieve this through lemma-style proving, multi-tiered inference strategies that integrate iterative refinement and broad conjecture generation, and a fast, specialized geometry engine.

29 Jul 2025
GRAPH-R1 proposes an agentic GraphRAG framework that uses end-to-end reinforcement learning for multi-turn interaction with knowledge hypergraphs, achieving consistently higher F1 scores across RAG benchmarks and reducing knowledge construction costs. This framework improves reasoning accuracy, retrieval efficiency, and generation quality in knowledge-intensive tasks.

31 Jul 2025
The research from the University of Science and Technology of China and Microsoft Research Asia introduces Gaussian Variation Field Diffusion (GVFDiffusion), a framework that enables high-fidelity 4D content generation from a single video input. This is achieved by creating a canonical 3D Gaussian Splatting representation and generating its temporal variations via a compact latent diffusion model, resulting in significantly faster generation times and improved quality compared to prior methods.
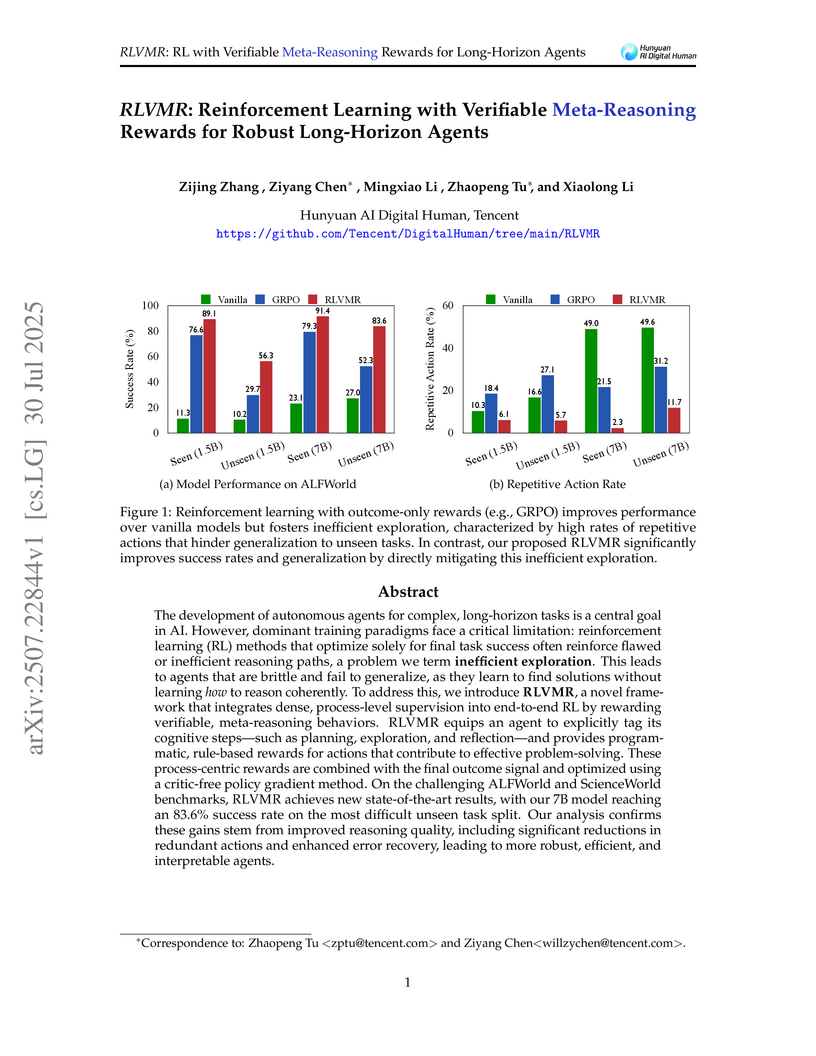
30 Jul 2025
RLVMR, developed by Tencent, trains Large Language Model agents to perform complex, long-horizon tasks by providing dense, verifiable meta-reasoning rewards during reinforcement learning. This approach leads to enhanced task success and generalization while significantly reducing inefficient exploration, such as repetitive and invalid actions, on benchmarks like ALFWorld and ScienceWorld.

31 Jul 2025
Researchers from Shanghai Jiao Tong University and Huawei developed SWE-Debate, a multi-agent debate framework leveraging graph-guided localization to resolve software issues. The system achieved a 41.4% Pass@1 success rate on the SWE-Bench-Verified dataset and 81.67% file-level localization accuracy on the SWE-Bench-Lite dataset.

31 Jul 2025
SWE-Exp introduces an experience-enhanced framework that enables Large Language Model agents to learn from past software issue resolution attempts, achieving a Pass@1 score of 41.6% on the SWE-bench-Verified dataset. It systematically captures and reuses knowledge via a multi-faceted experience bank and a dual-agent architecture, transforming agents from memoryless explorers into strategic, experience-driven problem solvers.